| Session | Date | Topic |
|---|---|---|
| 1 | 2025-04-23 | Introduction |
| 2 | 2025-04-30 | CCS Paper Potpourri |
| 3 | 2025-05-07 | Ethical and legal perspectives |
| 4 | 2025-05-21 | Digital trace data |
| 5 | 2025-05-28 | Digital trace data |
| 6 | 2025-06-04 | Automatic content analysis |
| 7 | 2025-06-11 | Automatic content analysis |
| 8 | 2025-06-18 | Automatic content analysis |
| 9 | 2025-06-25 | Automatic content analysis |
| 10 | 2025-07-02 | Simulation and computational experiments |
| 11 | 2025-07-09 | Simulation and computational experiments |
| 12 | 2025-07-16 | Q & A |
Computational Communication Science
Prof. Dr. Michael Scharkow
Sommersemester 2025
Session 1
CCS Module
- Computational Communication Science is mostly
- introduction to basic literature and methods
- very practical exercises in computational methods
- Datafied Society is more
- theory and research-focused
- (and probably has a unifying topic)
- Write your term paper in either of the classes.
Course credit and requirements
- active participation, i.e. by presenting a poster on a CCS study
- smaller homework assignments, i.e. practical computational methods
- term paper, preferably a data-driven analysis of your choice
- either as traditional 3000 word research paper or
- alternative forms, e.g. Scrollytelling
- fantastic example (in German): Blaue Bücher, rosa Bücher
- team work (in small teams) is more fun ad highly encouraged
English
- English is used for all spoken and written communication in the module
- English proficiency is never judged or graded
- the core difficulties in understanding the literature are rarely language-related
- CCS is almost exclusively based on English publications, with two notable intro book exceptions: Jünger & Gärtner (2023); Haim (2023)
Computational Communication Science?
A field is emerging that leverages the capacity to collect and analyze data at a scale that may reveal patterns of individual and group behaviors. (Lazer et al., 2009)
[W]e define computational communication science as the endeavor to understand human communication by developing and applying digital tools that often involve a high degree of automation in observational, theoretical, and experimental research. (Hilbert et al., 2019)
Computational Communication Science
- definition based on methods rather than study subject or theoretical background
- somehow “big data” are involved, as are automatic methods
- terminology and many methods mostly derived from the natural sciences and engineering
- innovation often (but not always) happens outside academia, e.g. within companies such as Google or Meta
Computational methods
- the “Big 3” approaches in CCS:
- automatic content analysis
- analysis of digital traces and digital behavioral data
- simulation and agent-based modelling
- historically, very strong emphasis on web data and automatic content analysis (Van Atteveldt et al., 2022)
- agent-based modeling still very niche topics (see your own study choices for next week!)
Schedule
Challenges
- data access for academic research (Freelon, 2018)
- legal and ethical challenges in using private or semi-public data
- technical and methodological issues in analyzing very large datasets
- necessary skills for students and scholars, lack of curricula
- computational studies are often (by necessity) interdisciplinary
- also: literacy for reviewing computational studies in communication research
Caveats
- the field is moving extremely fast, that means
- many approaches are outdated within a few years
- platforms restrict access to data and prohibit distribution of replication data
- replication of many studies is difficult
- starting from methods or data feels strange (and for some uncomfortable) compared to traditional empirical research
- you will need (and learn) coding skills at least in R, but might need Python later
Benefits
- computational skills are extremely valuable on the job market, both in academia and in the real world
- the CCS perspective challenges many traditional assumptions about how research works, i.e. by valuing creative re-operationalization of existing measures
- with a full methods toolbox, you can conduct high-quality research even on niche topics
- ideally the course will help you conduct better studies in your large empirical modules
Course setup
- “cold opening” introduction by actually reading CCS papers
- then, for every approach:
- I prepare a small presentation on the basics
- you work through an application using R at home
- we discuss the practical tasks in the following session
- we creatively apply the new methods to our own topics
- Bring your own ideas, data, research questions to class!
CCS Paper Potpourri
- 10 posters overall, we’ll probably do 2x 45min sessions.
- please bring the digital versions as well, just in case
- remember to get the posters printed ASAP
- any questions about the studies or posters?
Questions?
Session 2
CCS Paper Potpourri
- 2x 30 minutes/5 papers in the hallway
- presenters:
- think of a 30 second summary pitch to get the conversation started
- note/remember questions that came up repeatedly or were noteworthy
- audience
- provide interactions on the poster site (in English)!
- note/remember questions you’d like to discuss in class
Discussion
- Which paper/study do you remember best (and why)?
- Which study was the most difficult to understand (and why)?
- Which study would you like to replicate?
Next week
Session 3
Salganik (2018) I

Salganik (2018) I
- What are the main differences between Consequentialism and Deontology?
- How can the four mentioned ethical principles be applied to the experiment run by Munger (2017)?
- In case of doubt, what priority should these principles have among themselves?
Salganik (2018) II
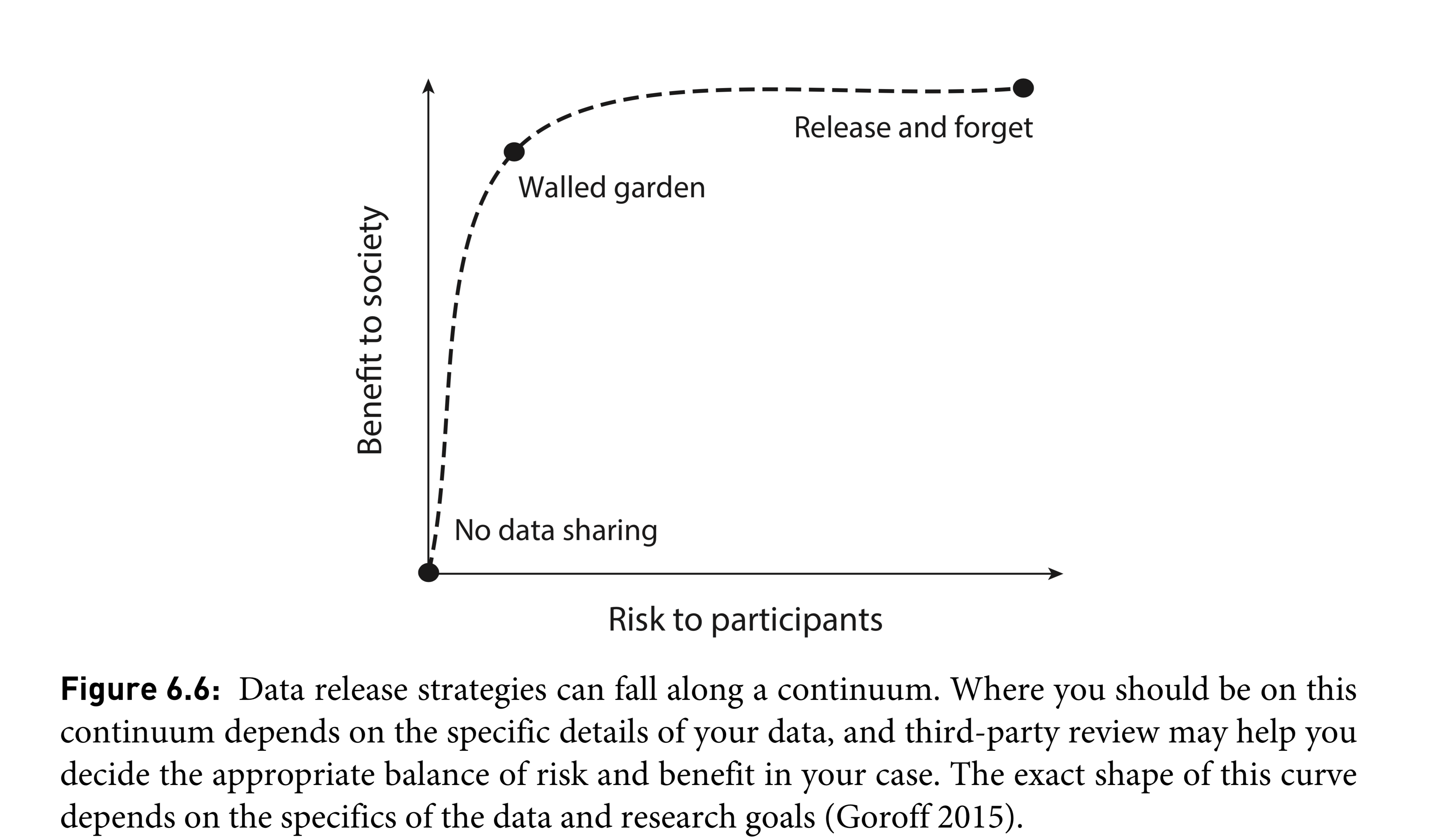
Research Ethics in Practice
- Is informed consent needed for a content analysis of social media posts from members parliament?
- What about comments on posts or public pages, e.g., from parties or politicians?
- What about Tinder profiles or other online dating platforms?
- What if informed consent is practically not possible?
Group Task
(four groups, 10 minutes)
- Summarise the design and execution of the Reddit AI experiment.
- What were the main points of criticism from the Reddit mods/legal people?
- What were the main rebuttals from the researcher team and UZH?
- Can you salvage the study idea and run it ethically? How?
API and non-API access
- free model (e.g. Wikipedia): everyone can get the data
- paid model (e.g. Twitter/X): you pay the platform or a third party for access
- grant model (e.g. TikTok): you can apply for access to the API as a scholar
- collab model (e.g. Meta): you can work with the platforms on spefific research questions
- data donation model: you ask participants to donate their DDP (Data Download Packages)
- independent/rogue model: you access a secret API or scrape the data otherwise
Post-API era
- most models have failed due to platforms (change of) self-interests (Freelon, 2018)
- commercial interests (i.e. monetization) or concerns about bad PR
- privacy concerns for well-meaning platforms https://en.wikipedia.org/wiki/Netflix_Prize
- “research data” incomplete and at times worse than public data
- big collaborations like Social Science One failed miserably and publicly
- other were challenging (Wagner, 2023) and ultimately problematic (Bagchi et al., 2024)
Issues with online data
- not all available online data can/should be considered public
- privacy vs. reproducibility vs. ethics vs. legal questions
- many instances of well-meaning research with unethically obtained data
- many instances of unethical research
- second and third order effects, e.g. LLM training data or vision models
- plus biases, errors, etc.
Questions
- When can you scrape and use online data (against the platforms terms)?
- Can you use an AI model based on unethical, possibly illegal training data?
- How can you ensure reproducible findings with problematic data?
Next session (in 2 weeks!)
- Get data dwnload packages (DDP) for all major online platforms/services that you use (at least 2), e.g. from Google/Youtube, Instagram, TikTok, Spotify, Netflix, etc.
- How? Google “data download package [PLATFORM]”
- Request JSON files if given the option between multiple formats
- Read Ohme et al. (2023)
Session 4
Digital trace data
- people’s online activities are constantly logged client- and server-side
- digital trace data from users are unobtrusively and continuously collected (by platforms or researchers)
- trace data are (less) subject to common biases in self-reports, e.g. memory or social desirability (Scharkow, 2016)
- trace data are subject to different biases, most notably selection bias (i.e. who we get data from)
- excellent Gesis Guides
API data
- mostly only public content data with few meta data, e.g. time stamps and account information
- pure usage data very rarely available from an API, and mostly only aggregated
- very rare for any large platforms, severe privacy concerns for individual-level data
- example 1: Wikipedia Views API, aggregate views per day
- example 2: Spotify API, 50 recently played tracks only from the logged-in user, can be used for automatic data donations (Ernst et al., 2024)
Web tracking data
- collected from devices using dedicated tools (e.g. browser plugins) or system logs
- technically difficult: mostly per-device, not per user tracking (Scharkow, 2016)
- severe privacy concerns, even with temporary user opt-out and/or whitelisting
- most researchers obtain tracking data from third parties (e.g. Respondi panel)
- extensive processing necessary (Clemm von Hohenberg et al., 2024)
- raw data is rarely public (exception: https://zenodo.org/records/4757574)
Data donations
- collected from users who requested their data download packages (DDP) from platforms
- for large platforms, potentially very large DDP, which require filtering before upload
- DDP uploaded via browser, using dedicated tools (e.g. DDM) or custom scripts
- (presumably) fewer trust and privacy issues, but requires motivated and skilled respondents (Pfiffner & Friemel, 2023)
- single-platform, single-user, but multi-device data
- mostly in standardized (JSON) format, but with ever-changing variables and labels
Platform tracking + donations
- Zeeschuimer browser extension tracks exposure to specific platforms
- TikTok, Instagram, X/Twitter, LinkedIn, Pinterest, etc.
- while active, logs exposure to content, along with content metadata
- logs can be sent to online server, or downloaded and donated manually
- works well for lab experiments, linkage studies, etc. that combine use + content data
- requires very active participation and data management strategies
Collecting digital trace data
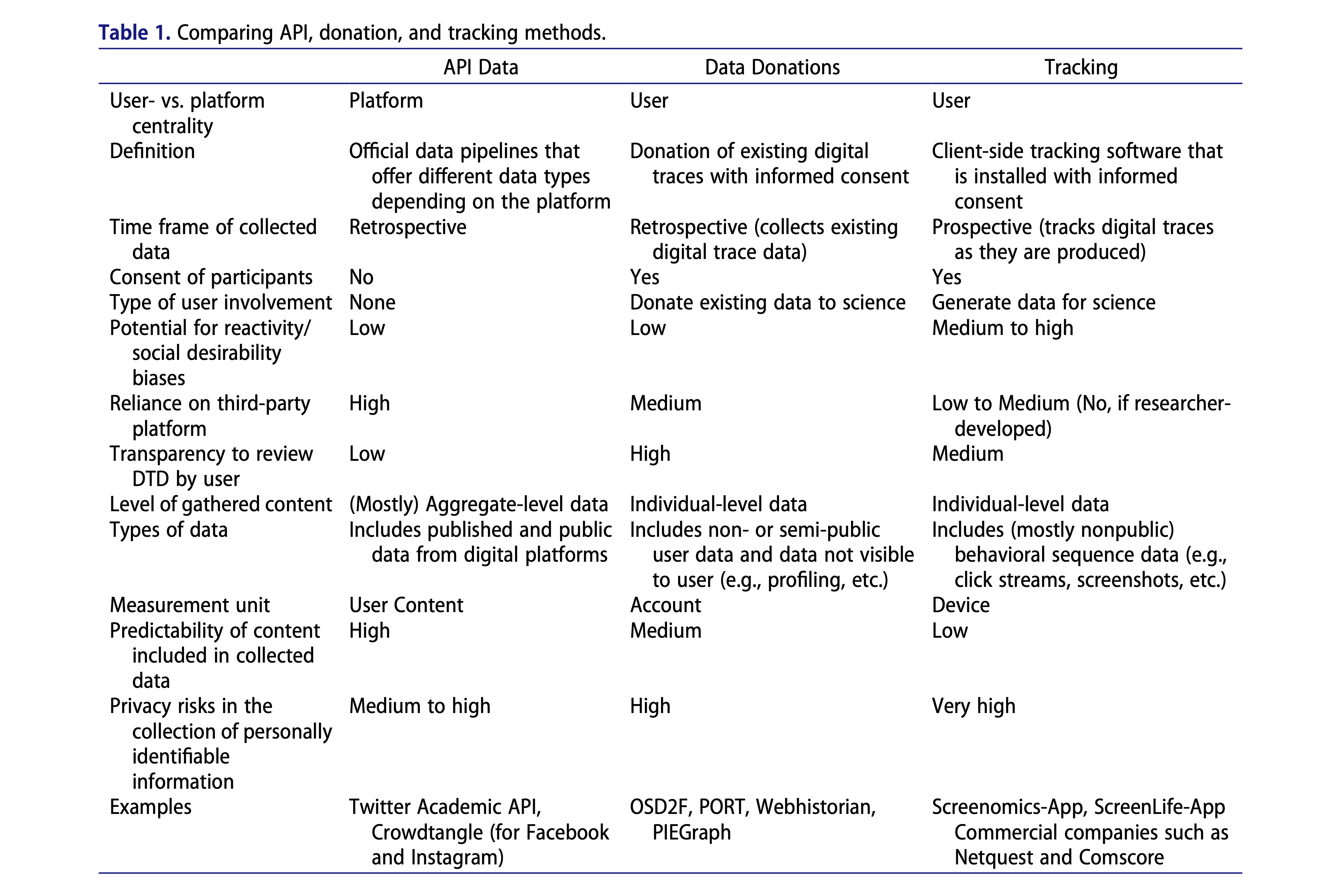
Source: Ohme et al. (2023)
Questions
- For which platforms did you obtain DDP?
- How difficult was it, how hard would it be for a regular respondent?
- Have you looked at the data? What did you find (interesting)?
Homework
- You need to complete three homework assignments, at least one per topic (trace data, content analysis, simulation/experiments).
- You can submit each homework until the start of the next topic (e.g. from now until we start with content analysis).
- You can submit in any format you like (I suggest Quarto HTML), but it should be self-explanatory.
- You can and are encouraged to work in pairs.
- Homework is, as always, pass or fail.
Practice
Trace data I
- Data Download Packages
- Zeeschuimer browser logs
Trace data II
- Aggregating and processing digital trace data
- Linking digital traces to survey or content data
Session 5
JSON data
- (How) did you successfully read your a single JSON file?
- How can we read multiples files?
list.files()&map()functions
Session detection
- Describe the basic algorithm to detect sessions.
- What assumptions do we have to make about user behavior?
- How can we define sessions for (a) browser or (b) phone log files?
Combining data
- What is the difference between
join(),left_join()andright_join()? - What kinds of data would you try to combine for a research project?
Session 6
Data Collection for Content Analysis
Methods for data collection (using R), from simplest to most complex:
- Directly import machine-readable files from the web (e.g., CSV).
- Use pre-built R packages for specific platforms/providers.
- Obtain semi-standardized data via APIs.
- Download and process HTML content from websites using web scraping.
- Collect content or take screenshots using remotely controlled browsers.
- Request data donations from users.
Machine-readable files
- Download and read structured data files (like CSV, JSON, XML) that are publicly available online
- Benefit: Often the easiest and most reliable way to obtain data when available
- Drawbacks: Limited availability, needs some searching
- Examples:
Specific R packages
- Benefit: Simple to install in R, pre-processed or readily accessible text data
- Drawbacks: Very limited scope, sometimes not up-to-date
- Examples:
gutenbergr: Accessing literary works from Project Gutenberg.manifestoR: Contains annotated party manifestos from many countries and years from the Manifesto projecttaylor: Provides song data, including lyrics for the Taylor Swift discography
RSS Feeds
- Benefit: Provides standardized, structured updates for frequently changing content.
- Drawbacks: Content often limited to headlines/summaries, may not include full text; feeds can be discontinued or change formats.
<?xml version="1.0" encoding="UTF-8"?>
<rss version="2.0">
<channel>
<title>Minimal News Feed</title>
<link>http://www.example.com/news</link>
<item>
<title>First Example News Story</title>
<link>http://www.example.com/news/story1.html</link>
<description>This is a brief summary of the first example news story.</description>
</item>
</channel>
</rss>JSON APIs
- Benefit: Provides structured, flexible data (JSON format); often allows for specific queries and filters.
- Drawbacks: Requires understanding of API documentation; rate limits and authentication (API keys) are common; APIs can change or be deprecated.
[
{
"quote": "I could have saved her.",
"author": "Walter White"
},
{
"quote": "So you're chasing around a fly and in your world, I'm the idiot?",
"author": "Jesse Pinkman"
}
]
Web Scraping
- involves extracting data from websites, and it’s particularly useful for content where APIs might not be available.
- HTML content is downloaded and parsed to extract specific elements (e.g., headlines, article bodies, dates).
- Challenges:
- Layout updates can break scraping code.
- Websites may block or limit automated access.
- Content loaded via JavaScript can be harder to scrape directly.
Scraping with remote-controlled browsers
- Utilizes automated browsers (e.g., Chrome, Firefox) to navigate websites, interact with elements, and extract content, mimicking human user behavior.
- Benefit: Can handle dynamic content (JavaScript, AJAX), login walls, and other complex interactive elements that traditional web scraping struggles with.
- Drawbacks:
- Significantly slower than direct HTML fetching as it renders the entire page.
- Requires setting up browser drivers (e.g., ChromeDriver, GeckoDriver).
- Still detectable by sophisticated anti-bot systems.
Data Donations
- Involves requesting and collecting data directly from users, who volunteer to share their digital information for research purposes.
- Benefit: Provides access to data from closed platforms (e.g., mobile apps, private social media groups) or highly personalized content that is otherwise inaccessible.
- Drawbacks:
- Data format and completeness can vary widely across platforms/donors.
- Sample may not be representative of the broader population.
- Requires robust infrastructure to collect and process diverse donated data.
Multimodal data
- Many platforms provide text as well as images or audiovisual data.
- Images and audiovisual data need to be downloaded before analysis.
- We can use the multimodal data directly or convert them to text (e.g. transcripts or image descriptions).
- Conversion to text makes things easier for us, but loses lots of information.
- Many useful tools available, e.g. for mass downloading, speech transcription, video-to-image conversion, etc.
Automatic content analysis
Text as Data
Textual data, often unstructured, needs to be transformed into a format suitable for computational analysis. Common representations include:
- Strings: The raw, sequential characters of text (e.g., “This is a sentence.”). This is the most basic form, preserving the original wording.
- Term-Document Matrices (TDMs) / Document-Term Matrices (DTMs): Numerical representations where rows are documents and columns are terms (words), with cell values indicating term frequency (or presence) in a document. This focuses on word counts and relationships across documents.
- Word Embeddings: Vector representations of words in a high-dimensional space, where semantically similar words are located closer together. This captures semantic meaning and context.
Text as Strings
| document_id | text_content |
|---|---|
| 1 | The quick brown fox jumps over the lazy dog. |
| 2 | A lazy cat sleeps on the mat. |
| 3 | The fox and the dog are friends. |
Text as Term-Document Matrix
- Term-Document Matrix (TDM) quantify word occurrences.
- Each column is a unique term, each row is a document, and cells indicate how often a term appears in a document.
document | brown | cat | dog | fox | friends | jumps | lazy | mat | quick | sleeps |
|:|:|:-|:-|:-|:–|:|:–|:-|:|:-| | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | | 2 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | | 3 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
Text as Word Embeddings
- Word or sentence embeddings represent text as numerical vectors, capturing semantic relationships.
- We can use vector arithmetic to compute semantic relations like
queen = king - man + woman. - The embedding dimensions themselves have no interpretable meaning to us.
Sentence ID | Dim 1 | Dim 2 | Dim 3 | Dim 4 | Dim 5 | Dim 6 | Dim 7 | Dim 8 | Dim 9 | Dim 10 |
|:|:|:|:|:|:|:|:|:|:|:-| | 1 | 0.78 | 0.15 | 0.92 | 0.23 | 0.65 | 0.42 | 0.81 | 0.19 | 0.70 | 0.33 | | 2 | 0.21 | 0.89 | 0.10 | 0.77 | 0.33 | 0.95 | 0.05 | 0.68 | 0.25 | 0.87 | | 3 | 0.62 | 0.35 | 0.75 | 0.12 | 0.88 | 0.08 | 0.59 | 0.30 | 0.91 | 0.17 |
Traditional automatic content analysis
- Preprocess the data
- remove stopwords or infrequent terms
- resolve anaphora or homonyms
- detect entities, negations, fixed phrases
- Convert text to term-document matrix or text embeddings.
- Use unsupervised or supervised machine learning, dictionaries, or other approaches
- Get predictions (i.e. categories) per document or term
- extensive literature, e.g. Scharkow (2013);Van Atteveldt et al. (2022)
Large Language Models (LLM)
- Models train on vast internet text (books, articles, websites) and learn contextual word embeddings, i.e. word vectors change based on surrounding words (e.g., “river bank” vs. “money bank”), capturing nuanced meaning.
- Reinforcement Learning from Human Feedback (RLHF): Human rankings of LLM responses to instructions train a reward model. The LLM then optimizes its responses to maximize this reward.
- Given a prompt, the LLM uses its learned knowledge to predict the most probable word sequence for a response.
- LLM can be used for many tasks: translation, summarization, text editing, etc.
- LLM Explainer by the FT, RLHF explainer by OpenAI
Large Multimodal Models (LMMs)
- Beyond text, LMMs integrate modalities like text, images, audio, or video, unlike text-focused LLMs.
- Specifically trained to understand and generate image-related content
- LMM learn to represent different modalities in a shared “embedding space,” understanding how text relates to visuals.
- LMM can perform tasks like image captioning, visual question answering, image generation from text, and object recognition.
Content analysis with LLM/LMM
- Zero-Shot/Few Shot Coding, the LLM performs a task with no or few specific examples, relying solely on a clear instruction in the prompt
- Benefits:
- No preprocessing or training data necessary, can perform a wide array of tasks.
- We can simply re-use coding instructions for manual content analysis.
- Often better at understanding subtle meanings and complex tasks/contexts.
- Drawbacks:
- LLM may inherit and amplify biases present in their training data.
- Using commercial LLM APIs can be costly, and coding is relatively slow.
- Performance can vary significantly with minor changes in prompt wording or the selection of few-shot examples.
AI-based content analysis
- In this course, we use LLM/LMM for basically all content analysis tasks.
- Basic workflow is similar to manual content analysis:
- Collect the content data to be coded (text, image, video, etc.).
- Develop codebook with coding instructions and examples.
- Combine instructions with text/image data to prompts for LLM API.
- Collect structured predictions for each coding unit from the model.
- Maybe combine different predictions (varying tasks, varying LLM/LMM)
- Always validate with human coding!
Tasks
- Install python tools in our RStudio server:
pipx install yt-dlp vcsi whisper-ctranslate2 && pipx ensurepath, then start a new terminal. - Try out
yt-dlpin the new terminal. - Work through the data collection examples
You need to re-download the ZIP file and data for the next sessions. Sorry!
Session 7
Questions about coding tasks?
- tabular data and R packages
- JSON and RSS APIs
- web scraping
- downloading images and videos
- any additional sources?
Automatic text analysis
- working with text strings
- basic text analysis and regular expressions
Zero-shot classification
- get your API key from https://ki-chat.uni-mainz.de/
- try out in the regular chat interface
Session 8
Questions about coding tasks?
- string manipulation and regular expressions
- LLM API requests
- structured JSON responsed and types
- end-to-end coding pipelines
Image and video coding
Whisper transcriptions and vcsi video-to-image
Large multimodal or visual models
How can we deal with multimodal content?
Computational workflows
- try to think in successive steps
- look up suitable code snippets to re-use
- ask me or a LLM, but provide as much detailed information as possible
- successively build pipelines and intermediate objects for your analysis
- get single tasks to work first, than run the same task repeatedly using
map()etc.
Term papers
- max (!) 5000 words, max 3 co-authors
- any communication-related topic, but the method must be computational
- classic scholarly paper, but also alternative formats
- deadline etc. as usual
- talk to me about research questions etc.
Session 9
Questions about coding tasks?
- video downloading and processing with external tools
- zero-shot image classification
Inspiration for term papers
blog posts: http://varianceexplained.org/r/trump-tweets/, https://observablehq.com/@uwdata/a2-example-movies-data
the pudding: https://pudding.cool/2024/11/love-songs/, https://pudding.cool/2023/05/country-radio/, https://pudding.cool/2017/03/punk/
data sources from Kaggle: Netflix content, Top Spotify Songs, TMDB Movies with Credits, etc.
Simulation and agent-based modeling
Classical Empirical Social Research
- Theory development in the form of verbal statements
- Theory testing based on empirical data
- (Null) hypothesis testing as a comparison of theory and empiricism
Simulations
- Theory development in the form of algorithms/code
- Generation of (multiple) simulated data
- Comparison of simulated data with empirical data
Types of Simulations
- Monte Carlo simulation
- Social simulations (Waldherr & Wettstein, 2019)
Monte Carlo Simulation
- Assumptions about the distribution of data in the population
- Repeated drawing of random samples from the population
- Repeated application of a procedure and analysis of the results
Advantages and Disadvantages of Monte Carlo Simulation
- Especially suitable for testing procedures (does my analysis do what it’s supposed to?) and for
- Power analysis (can my study find a specific effect?)
- Data-generating process must be known (approximately)
- Rule specification via formulas
- Isolated consideration of all cases (no interactions between agents)
Agent-Based Models (ABM)
Computer models with the following components:
- Agents
- Environment
- Rules
Suitable for modeling and simulating complex systems with
- Heterogeneous, interacting, and adaptive agents
- Dynamic, non-linear processes
- Micro-macro linkages
Simulation Specification
- In ABM, often relatively simple action rules
- Formal specification with a probabilistic components
- Few parameters within the agents, few for the environment
- Problem 1: Social science theory often not sufficiently specific and complete
- Problem 2: Model assumptions vs. simulation results
Generative Agent Models
- Instead of formal (programmed) rules we use verbal rules
- Use of an LLM as an agent (“Roleplaying”)
- LLM supplements verbal instructions and role with verbal responses
- Responses depend on training data and LLM quality
- Very few validation studies to date (Larooij & Törnberg, 2025)
- Often relatively naive assumptions about the generalizability of results (= substitute for human agents)
Hype
Outlook on LLM-based ABM
- Diverse application areas, especially in reception research
- Relatively simple rule specification, complex agent personas (possibly with memory)
- Easy to link with real stimuli
- Inter-agent communication possible, but not yet implemented in Expected Parrot
- Disadvantages: LLM biases shine through, unclear generalizability
- LLM responses are definitely not equivalent to human respondents!
Tasks for the next sessions
- Review practical exercise https://stats.ifp.uni-mainz.de/ma-ccs/generative-agents.html
- Complete homework in R
- Think about your term paper
- Learn Quarto publishing (practical exercise in 2 weeks)
Session 10
Questions about coding tasks?
- scraping headlines for testing
- creating a persona and generating prompts
- creating stimuli using LLM
- generating stimulus x persona combinations
- getting and analyzing results
Writing papers with statistical analyses
- Reproducible research is crucial for academic work.
- Traditional word processors present challenges like:
- Copy/paste errors: Introducing inconsistencies between code and results.
- Manual citation management: Prone to errors and time-consuming.
- Reproducibility concerns: Difficulty verifying results and replicating analyses.
Knitr and Quarto
- knitr integrates R code directly into your writing.
- It automates result inclusion, saving time and reducing errors.
- Quarto uses Pandoc for versatile document conversion.
- It combines R running code, text, and figures in one file.
- You can easily create reports in multiple formats.
- Code Example: `
{r} qplot(rnorm(100))– simple code execution.
Code example
Enhanced Features for Academic Writing
- Cross-referencing simplifies citing figures and tables.
- Callouts highlight important definitions and caveats.
- Automatic numbering of sections improves readability.
- Quarto ensures consistent formatting throughout your paper.
Term Paper Specific Benefits
- Easily include statistical analyses and visualizations.
- Automated bibliography generation with BibTeX or CSL.
- Maintain a clear record of your data analysis steps.
- Share your code and results for transparency and verification.
- Compared to Word: reduces manual formatting, copy/paste and citation errors.
Multiple Output Formats
- Create PDFs for submission to professors and journals.
- Generate HTML reports for online presentations and sharing.
- Export to Word (.docx) for compatibility with specific requirements.
- Compared to Word: simplifies converting between formats automatically.
- Beyond the Basics:
- Slides: Create presentation slides (like these!) directly from your document.
- Closeread: Generate scrollytelling narratives with interactive data visualizations.
Quarto Resources
- Quarto Website: https://quarto.org/
- Quarto Gallery: https://gallery.quarto.org/
- Quarto R Documentation: https://quarto.org/docs/language/r/
- Closeread https://closeread.dev/
Tasks for next week
- Check my basic term paper template, modify settings, text and code, check the resulting document.
- Collect questions you might have about how to accomplish certain tasks in Quarto.
Session 11
Questions about Quarto?
IfP Quarto website: https://github.com/ccsmainz/ma-datenanalyse
Visual mode
- RStudio provides a visual mode for editing
- it enables you to work using menus and clicking
- especially useful for citations, images and tables
References
- citations in markdown are simply
@smith2022 - you can search and include references in visual mode, based on DOI
- the Bibtex entry is automatically generated and added to your references file
- similarly, there is a Zotero connector if you already use Zotero’s online library
Code
- for smaller documents, writing all your code in the respective chunks works fine
- for longer documents, move the computations etc. into a separate chunk at the top, then reference only the computed objects in the document
- alternatively: work on your code in a regular R file, and use
source("mycode.R")in the first chunk - for expensive computations use either caching or write the results into a dedicated file
saveRDS(my_regression_model, "reg1.rds")
Visual branding
- Quarto documents can be customized either through YAML header options like
mainfontor with a brand file - use a
_brand.ymlfile in the same folder, which includes many visual options like colors, fonts, styles - works for HTML, RevealJS slides, and some parts of PDF documents
- does not impact the ggplot2 graphics, for which you’d need to set theme, colors, etc. separately
_brand.ymlinstructions
Closeread
- a Quarto extension specifically for Scrollytelling articles
- mainly two features: stickies and focus effects (panning, scrolling, zooming, highlighting)
- stickies can be text, regular images or computed images (e.g. ggplot2 graphics)
- create fake animations by successively adding layers to your plot, e.g. you start with an empty plot, and add
geom_* - Closeread prize winners all have github repositories, so you can read and copy code
References
Bachl, M. (2018). (Alternative) media sources in AfD-centered facebook discussions. Studies in Communication | Media, 7(2), 256–270. https://doi.org/10.5771/2192-4007-2018-2-128
Bachl, M., & Scharkow, M. (2015). Eine quantitative Bestandsaufnahme von Informationen über Krankheiten auf der deutschsprachigen Wikipedia, 2002-2014. In E. Baumann & M. Hastall (Eds.), Gesundheitskommunikation im gesellschaftlichen Wandel (pp. 93–104). Nomos. https://doi.org/10.5771/9783845264677-93
Bagchi, C., Menczer, F., Lundquist, J., Tarafdar, M., Paik, A., & Grabowicz, P. A. (2024). Social media algorithms can curb misinformation, but do they? arXiv. https://doi.org/10.48550/ARXIV.2409.18393
Clemm von Hohenberg, B., Stier, S., Cardenal, A. S., Guess, A. M., Menchen-Trevino, E., & Wojcieszak, M. (2024). Analysis of Web Browsing Data: A Guide. Social Science Computer Review, 42(6), 1479–1504. https://doi.org/10.1177/08944393241227868
Ernst, A., Dietrich, F., Rohr, B., Reinecke, L., & Scharkow, M. (2024). Revisiting the digital jukebox in daily life: Applying mood management theory to algorithmically curated music streaming environments. http://dx.doi.org/10.31234/osf.io/7eb4g
Freelon, D. (2018). Computational Research in the Post-API Age. Political Communication, 35(4), 665–668. https://doi.org/10.1080/10584609.2018.1477506
Haim, M. (2023). Computational Communication Science. Springer Fachmedien Wiesbaden. https://doi.org/10.1007/978-3-658-40171-9
Hilbert, M., Barnett, G., Blumenstock, J., Contractor, N., Diesner, J., Frey, S., González-Bailón, S., Lamberson, P., Pan, J., Peng, T.-Q., et al. (2019). Computational communication science: A methodological catalyzer for a maturing discipline. International Journal of Communication, 13, 3912–3934.
Jünger, J., & Gärtner, C. (2023). Computational Methods für die Sozial- und Geisteswissenschaften. Springer Fachmedien Wiesbaden. https://doi.org/10.1007/978-3-658-37747-2
Larooij, M., & Törnberg, P. (2025). Do large language models solve the problems of agent-based modeling? A critical review of generative social simulations. https://doi.org/10.48550/ARXIV.2504.03274
Lazer, D., Pentland, A., Adamic, L., Aral, S., Barabási, A.-L., Brewer, D., Christakis, N., Contractor, N., Fowler, J., Gutmann, M., et al. (2009). Computational social science. Science, 323(5915), 721–723.
Munger, K. (2017). Tweetment effects on the tweeted: Experimentally reducing racist harassment. Political Behavior, 39(3), 629–649. https://doi.org/10.1007/s11109-016-9373-5
Ohme, J., Araujo, T., Boeschoten, L., Freelon, D., Ram, N., Reeves, B. B., & Robinson, T. N. (2023). Digital Trace Data Collection for Social Media Effects Research: APIs, Data Donation, and (Screen) Tracking. Communication Methods and Measures, 18(2), 124–141. https://doi.org/10.1080/19312458.2023.2181319
Parry, D., & Toth, R. (2025). Extracting Meaningful Measures of Smartphone Usage from Android Event Log Data: A Methodological Primer. Computational Communication Research, 7(1), 1. https://doi.org/10.5117/ccr2025.1.8.parr
Pfiffner, N., & Friemel, Thomas. N. (2023). Leveraging Data Donations for Communication Research: Exploring Drivers Behind the Willingness to Donate. Communication Methods and Measures, 17(3), 227–249. https://doi.org/10.1080/19312458.2023.2176474
Salganik, M. (2018). Bit by bit: Social research in the digital age. Princeton University Press.
Scharkow, M. (2013). Thematic content analysis using supervised machine learning: An empirical evaluation using german online news. Quality & Quantity, 47(2), 761–773.
Scharkow, M. (2016). The accuracy of self-reported internet use. A validation study using client log data. Communication Methods and Measures, 10(1), 13–27. https://doi.org/10.1080/19312458.2015.1118446
Van Atteveldt, W., Trilling, D., & Calderón, C. A. (2022). Computational analysis of communication. Wiley Blackwell.
Wagner, M. W. (2023). Independence by permission. Science, 381(6656), 388–391. https://doi.org/10.1126/science.adi2430
Waldherr, A., & Wettstein, M. (2019). Bridging the gaps: Using agent-based modeling to reconcile data and theory in computational communication science. International Journal of Communication, 13(00), 24. https://ijoc.org/index.php/ijoc/article/view/10588
Social Simulations