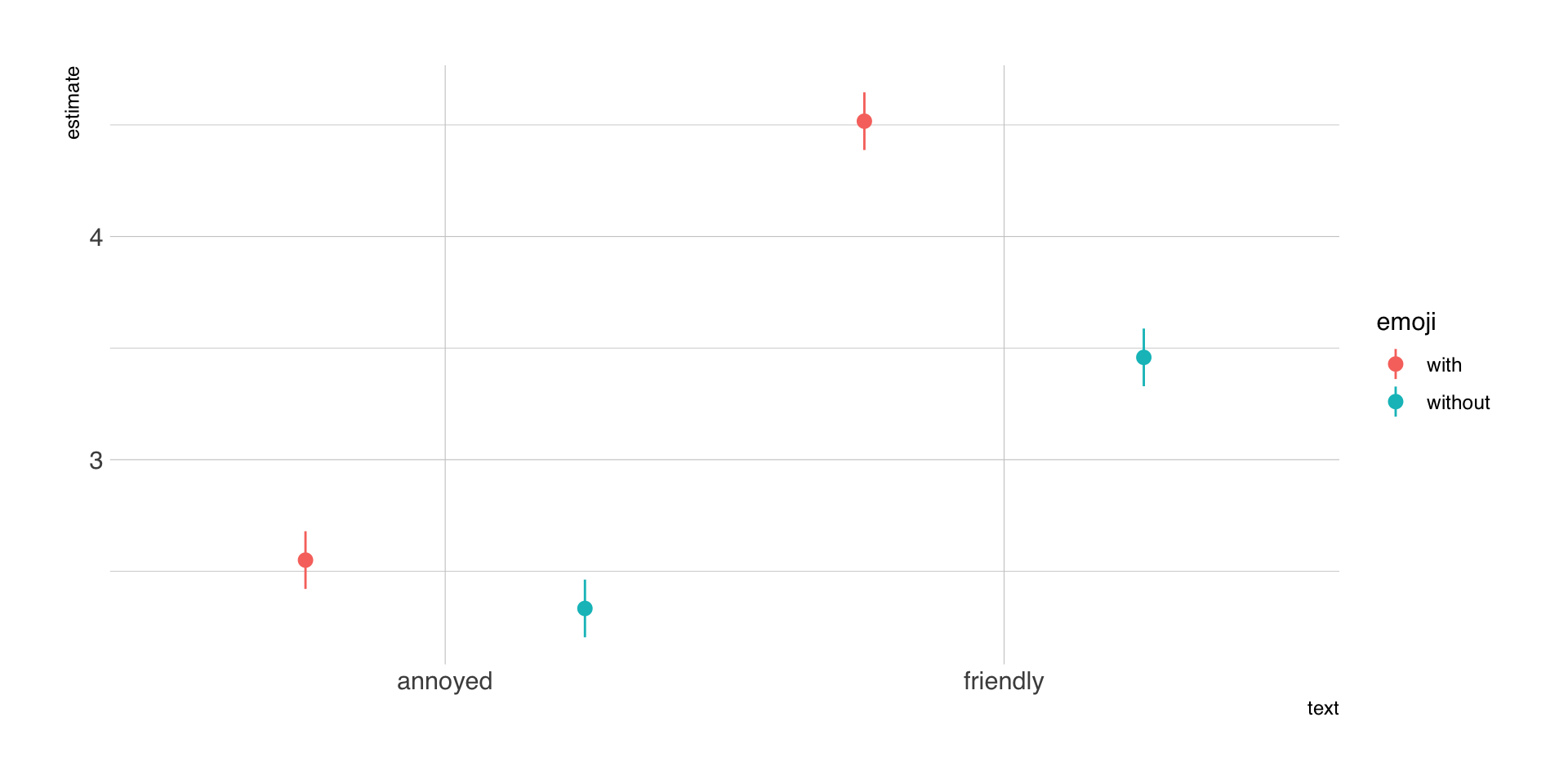
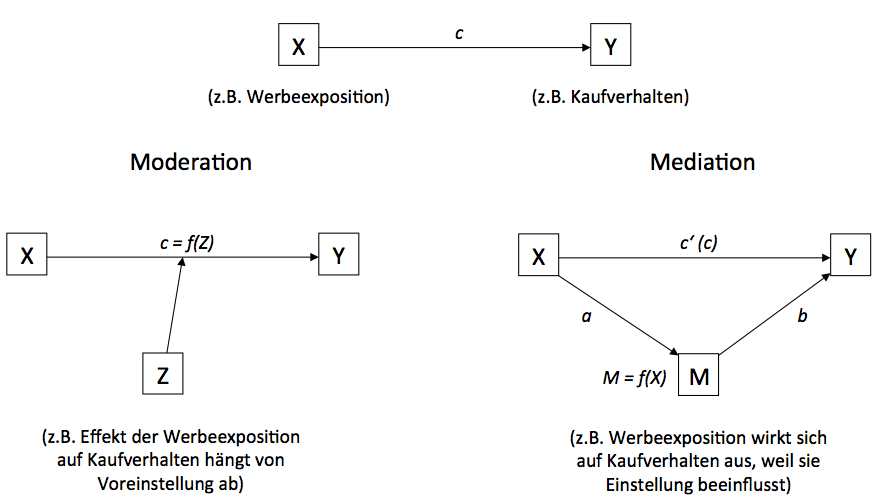
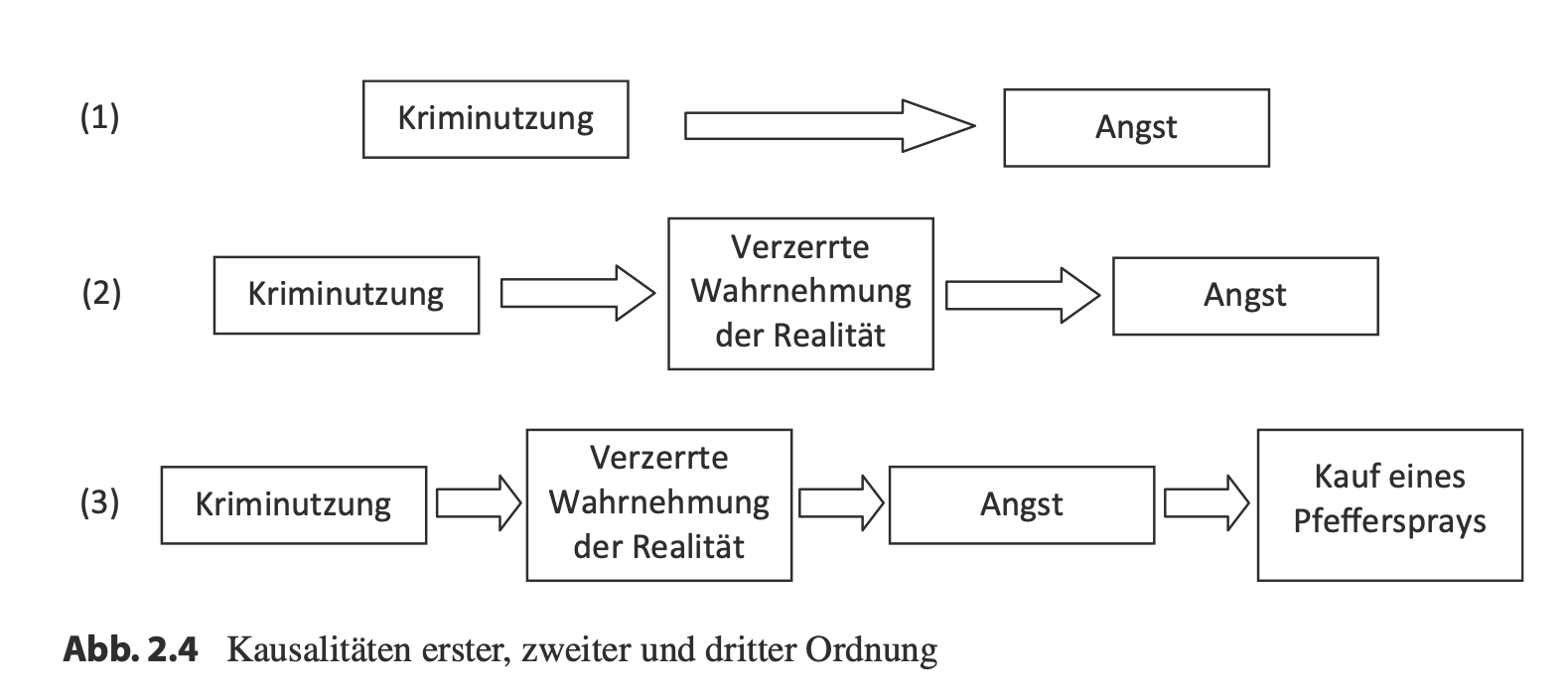
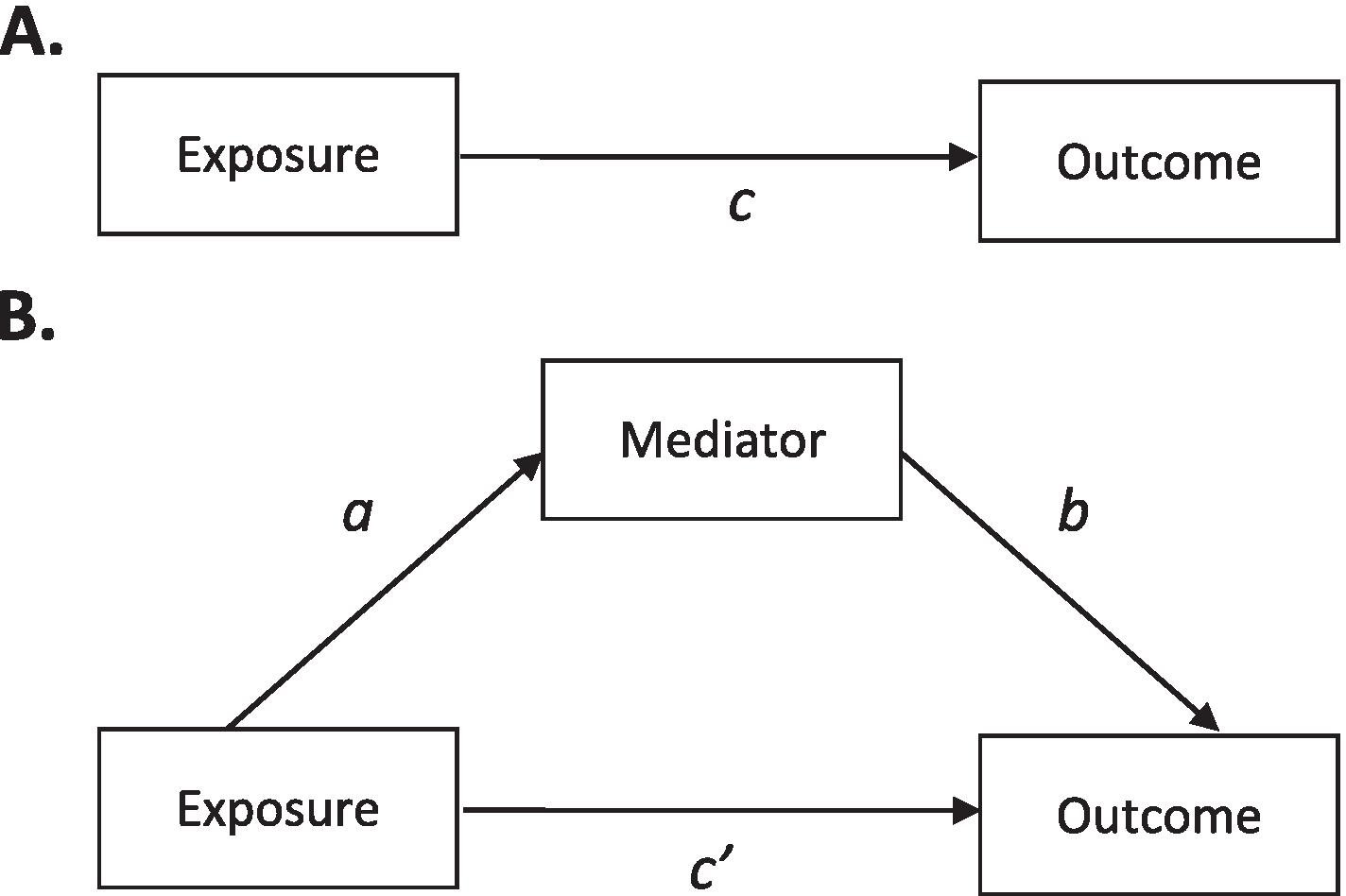
Bullock, J. G., Green, D. P., & Ha, S. E. (2010). Yes, but what
’s the mechanism? (don
’t expect an easy answer).
Journal of Personality and Social Psychology,
98(4), 550–558.
https://doi.org/10.1037/a0018933
Koch, T., Peter, C., & Müller, P. (2019).
Das experiment in der kommunikations- und medienwissenschaft. Springer Fachmedien Wiesbaden.
https://doi.org/10.1007/978-3-658-19754-4
Larooij, M., & Törnberg, P. (2025).
Do large language models solve the problems of agent-based modeling? A critical review of generative social simulations.
https://doi.org/10.48550/ARXIV.2504.03274
Rijnhart, J. J. M., Lamp, S. J., Valente, M. J., MacKinnon, D. P., Twisk, J. W. R., & Heymans, M. W. (2021). Mediation analysis methods used in observational research: a scoping review and recommendations.
BMC Medical Research Methodology,
21(1).
https://doi.org/10.1186/s12874-021-01426-3
Waldherr, A., & Wettstein, M. (2019). Bridging the gaps: Using agent-based modeling to reconcile data and theory in computational communication science.
International Journal of Communication,
13(00), 24.
https://ijoc.org/index.php/ijoc/article/view/10588
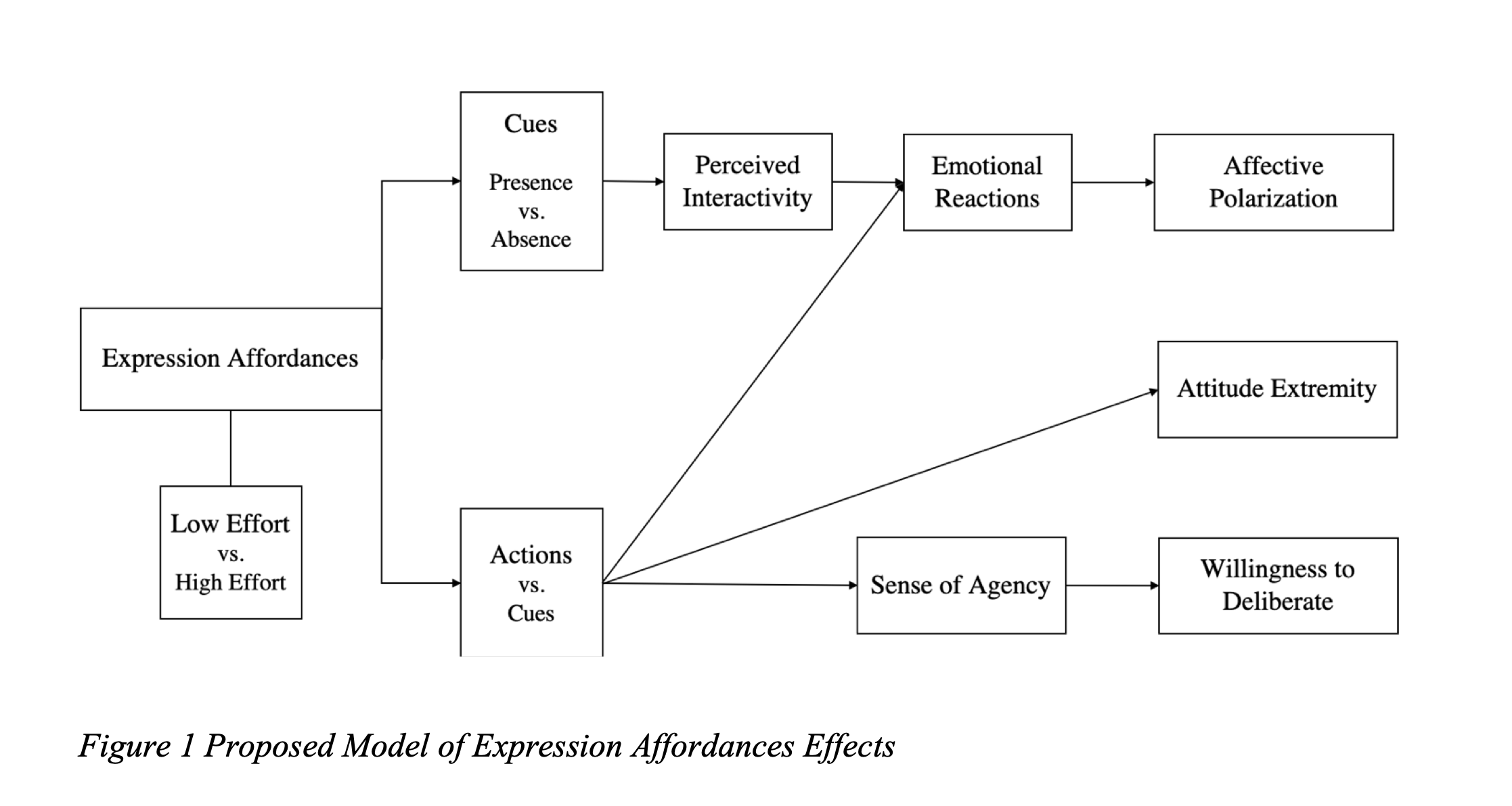
Wang, J., & Sundar, S. S. (2022). Liking versus commenting on online news: effects of expression affordances on political attitudes.
Journal of Computer-Mediated Communication,
27(6).
https://doi.org/10.1093/jcmc/zmac018