| Sitzung | Datum | Thema |
|---|---|---|
| 1 | 28.10.2025 | Einführung und Grundlagen |
| 2 | 04.11.2025 | Themenwahl und Forschungsfragen |
| 3 | 11.11.2025 | CCS: Datenerhebung |
| 4 | 18.11.2025 | Studiendesign und Stichprobe* |
| 5 | 25.11.2025 | Kategorien und Codierung* |
| 6 | 02.12.2025 | CCS: Inhaltsanalyse mit LLM |
| 7 | 09.12.2025 | Codebuch-Finalisierung* |
| 8 | 16.12.2025 | Reliabilitätstest |
| 9 | 06.01.2026 | Feldphase (keine Sitzung) |
| 10 | 13.01.2026 | Datenaufbereitung und -analyse* |
| 11 | 20.01.2026 | CCS: Zero-Shot Codierung I |
| 12 | 27.01.2026 | CCS: Zero-Shot Codierung II |
| 13 | 03.02.2026 | Visualisierung und Ergebnisaufbereitung |
| 14 | 10.02.2026 | Abschluss |
Inhaltsanalyse: Inhalte öffentlicher Kommunikation
Prof. Dr. Michael Scharkow
Wintersemester 2025/26
Sitzung 1
Lernziele
- Wie führen wir ein Forschungsprojekt durch?
- Wie koordinieren und managen wir ein komplexes Projekt mit mehren Mitarbeitern unter Zeitdruck? (Projektmanagement)
- Wie präsentieren wir Projektfortschritte, Forschungsprozesse und Forschungsergebnisse?
- Wie geben wir konstruktives Feedback im Forschungsprozess? Wie nehmen wir Feedback an und setzen es um?
- Spaß haben in der Forschung!
Warum Computational Methods?
- mein Lehr- und Forschungsbereich
- hohe Nachfrage in der Kommunikationswissenschaft
- relevante Skills in vielen Jobs außerhalb der Wissenschaft (Data Science, Journalismus, Marktforschung)
- Ziel ist vor allem Verständnis der Grundlagen und Dinge ausprobieren
Inhalt
Literatur



Leistungen
Aktive Teilnahme
- aktive Mitarbeit in einer Arbeitsgruppe
- 1 Gruppenbericht zum Stand der Arbeit
- 3 Hausaufgaben zu CCS-Sitzungen
Prüfungsleistung
- Projektbericht als Gruppenhausarbeit
Studentische Arbeitsgruppen
- i.d.R. 4-5 Studierende pro Gruppe (= max. 5 Gruppen im Seminar)
- ‚Learning by doing’ in der AG
- von anderen AGs lernen über andere Methoden, Themen und Arbeitsweisen
- Lernen von Feedback zur eigenen Arbeit und der Arbeit der anderen AGs
Gruppenberichte
- jedes Gruppenmitglied ist federführend für einen Bericht
- Protokollierung des Diskussionsprozesse in der AG seit dem letzen Bericht
- Vorbereitung einer zusammenfassenden Kurzpräsentation (5 min) mit 2-3 Folien
- Upload der Folien spätestens Di, 8h in Moodle
- alle anderen geben Feedback für eigene und andere AG
Sitzungen zu CCS
- Inverted Classroom, d.h. verpflichtende Vorbereitung
https://stats.ifp.uni-mainz.de/ba-ccs-track/ - Hausaufgaben für jede CCS-Sitzung, Abgabe jeweils Mo, 12h in Moodle
- eigenes Notebook zu den praktischen Sitzungen mitbringen
- wir verwenden R und RStudio, https://rstudio.ifp.uni-mainz.de
- gern paarweise arbeiten, das hilft in der Sitzung und macht mehr Spaß
Hausarbeiten
- Gruppenhausarbeit als Modulprüfung
- maximal (!) 10 Seiten pro Gruppenmitglied, max. 10.000 Wörter insgesamt
- Dokumentation der eigenen Arbeit, d.h. Gruppenberichte können recycled werden
- es muss nichts “rauskommen”, außer dass sie etwas gelernt haben
- Formalien und Regeln wissenschaftlicher Arbeit sind wichtig und notenrelevant
Was ist Inhaltsanalyse?
Definitionen
„Content analysis is a research technique for the objective, systematic, and quantitative description of the manifest content of communication.” (Berelson 1952, S. 18)
„Die Inhaltsanalyse ist eine empirische Methode zur systematischen, intersubjektiv nachvollziehbaren Beschreibung inhaltlicher und formaler Merkmale von Mitteilungen” (Früh, 1998, S.24)
“Content analysis is a research technique for making replicable and valid inferences from texts (or other meaningful matter) to the contexts of their use.” (Krippendorff, 2004, S. 18)
Theorie der Inhaltsanalyse - Inferenzen
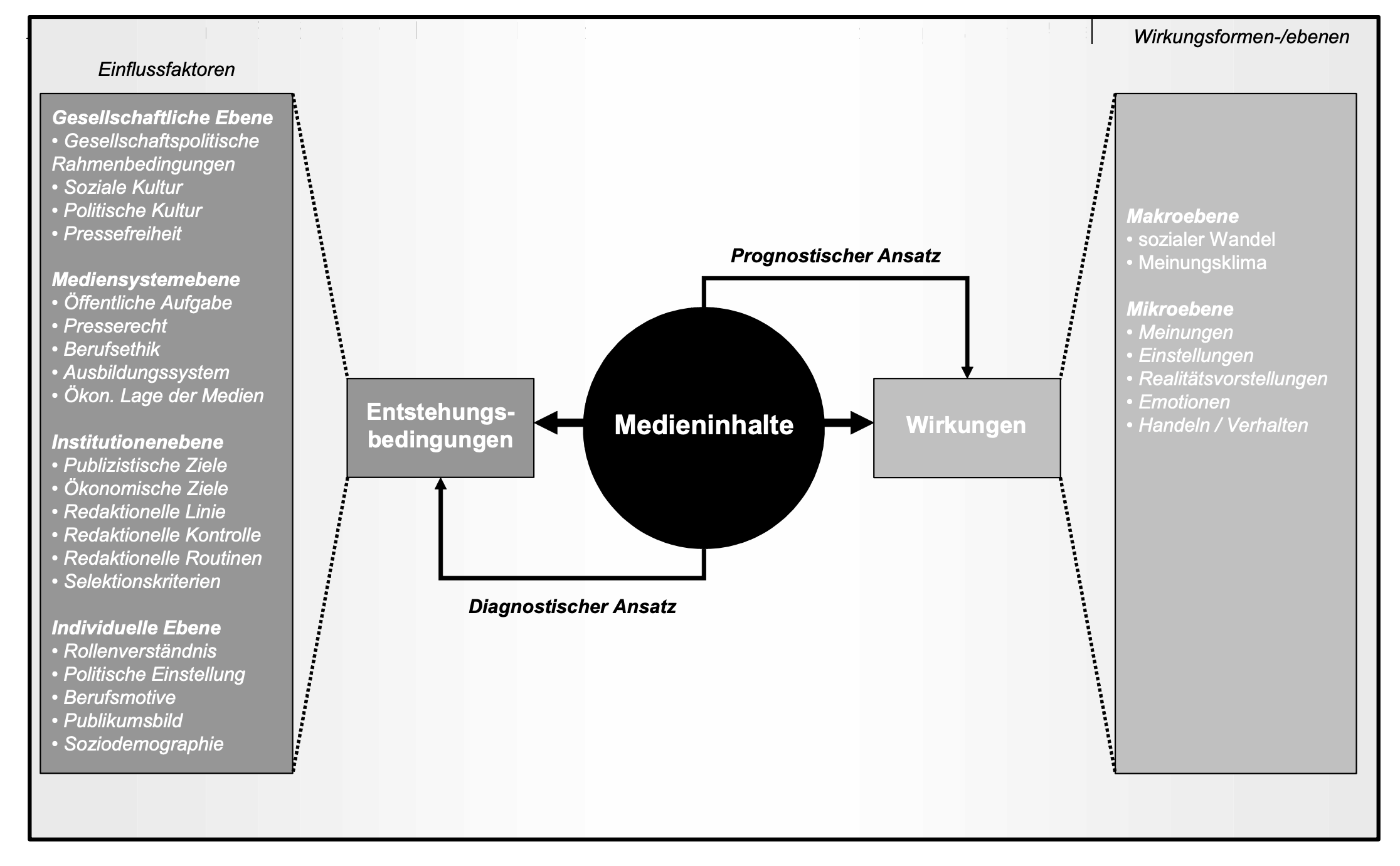
Quelle: Früh, 2007
Aufgabe
Diskutieren Sie in Paaren, wie nach Benoit et al. (2009) politische Positionen zu Aussagen werden, und welche Inferenzen wir durch Analysen dieser Aussagen ziehen können.
Hausaufgaben
- Bilden Sie Arbeitsgruppen (à 4-5 Personen) und entwickeln Sie erste Themenideen (ca. 1-3 Themen).
- Bringen Sie die Themenideen als kurze Pitches samt Forschungsfrage(n) mit.
Sitzung 2
Ihre Themenideen
Noch einmal: Inferenzen
Früh, 2007
Was ist eine gute Forschungsfrage?
- Eine Forschungsfrage ist eine Frage!
- Eine Forschungsfrage lässt sich empirisch beantworten, am besten mit der eigenen Inhaltsanalyse.
- Eine Forschungsfrage ist weder zu allgemein noch zu spezifisch.
- Eine Forschungsfrage hat oft eine (implizite oder explizite) Vergleichsdimension.
- Inhaltliche und methodische Forschungsfragen sind gleich relevant.
Was ist eine gute Hypothese?
- Eine Hypothese ist empirisch falsifizierbar, und es muss klar sein, wann sie falsifiziert ist.
- Eine Hypothese ist klar und widerspruchsfrei formuliert.
- Eine Hypothese ist einfach, komplexe Hypothesen sollten in einfache Hypothesen zerlegt werden.
- Es ist nicht schlimm, sich widersprechende Hypothesen zu formulieren (H1a vs H1b).
- Eine Nullhypothese ist selten eine interessante Hypothese, und oft nicht leicht zu prüfen.
Woher bekommt man gute Hypothesen?
- existierende Theorien mit klaren Annahmen
- existierende empirische Befunde (auch bei mehrdeutiger Ergebnislage)
- eigene Herleitung aus plausiblen, begründeten Annahmen
- nicht: 3 Sätze Alltagserfahrung
Begriffsarbeit
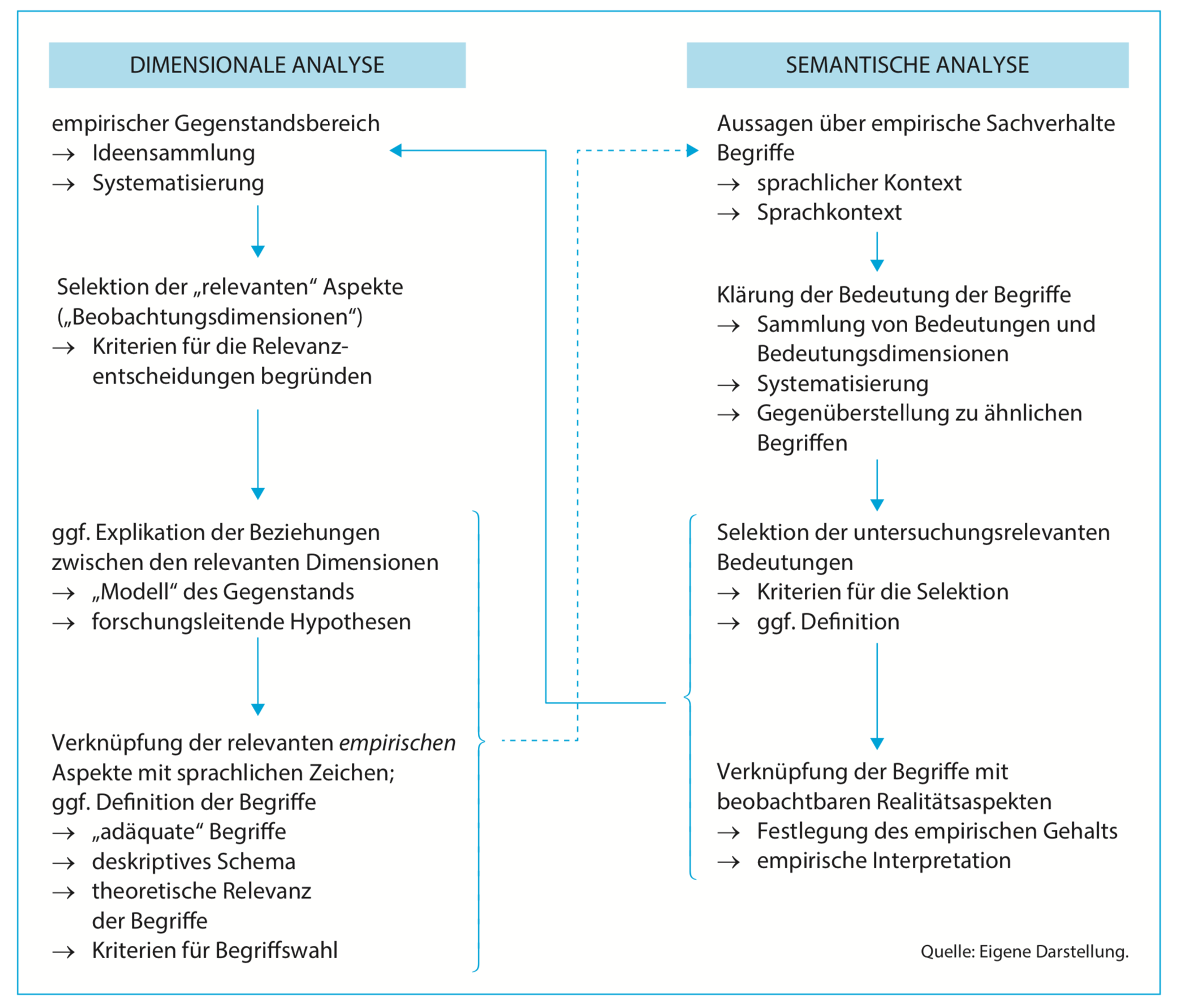
Quelle: Kromrey et al. (2016)
Fragen?
Aufgaben bis nächste Woche
- Recherchieren sie relevante Literatur zu ihrem Thema.
- Formulieren sie (eher allgemeine) 1-2 Forschungsfragen.
- Stellen sie 3-5 (eher konkrete) Hypothesen auf (mit Begründung!).
- Unterziehen Sie die für Ihre Studie relevanten Konstrukte einer dimensionalen und semantischen Analyse.
CCS Hausaufgabe
- Arbeiten Sie https://stats.ifp.uni-mainz.de/ba-ccs-track/ia-daten.html einmal durch
- Hausaufgabe ist in der übernächsten Woche fällig (spätestens, nicht frühestens!)
Sitzung 3
Erhebung von Inhalten für Inhaltsanalysen
- sehr viele Text- und Bild-Inhalte sind digital (und online) vorhanden, aber Zugang für wissenschaftliche Zwecke oft problembehaftet
- Problem 1: Vollständigkeit, z.B. durch selektive Rechtevergabe oder technische Zugangsbarrieren im Archiv
- Problem 2: Rechtslage/Copyright, wobei Forschung und Lehre stark priviligiert sind
- Problem 3: Ethische Fragen, etwa ob Individuen Schaden bei der Erhebung ersteht oder Zustimmung der Betroffenen vorliegt
- Problem 4: Praktische und methodische Fragen, etwa wie man möglichst zuverlässig Inhalte erheben kann
Online-Archive traditioneller Medien
- seitens der Anbieter, z.B. SPIEGEL oder ZEIT Archiv, Tagesschau Sendungsarchiv
- kommerzielle Datenbanken, z.B. LexisNexis oder Factiva
- GDELT (Global Database of Events, Language and Tone) und Mediacloud als riesige, nicht-kommerzielle Datenbanken (ohne Volltexte)
- NewsAPI als kommerzielle Datenbank mit einfachem Zugriff, aber limitiertem (kostenlosen) Zugang
Mobile Apps und andere geschlossene Systeme
- technisch extrem schwierig zu erheben durch Sandboxing auf Android/iOS
- Alternative 1: Überwachung und Mitschnitt von Netzwerk-Traffic
- Alternative 2: Data Donations von NutzerInnen, z.B. in Form von Screenshots (u.a. Screenome Project)
Datenerhebung mit R
Möglichkeiten, aufsteigend vom leichtesten zum schwierigsten
- maschinenlesbaren Dateien direkt aus dem WWW einlesen (z.B. CSV-Files)
- fertige R-Pakete für einzelne Plattformen/Anbieter verwenden
- über API (Application Programming Interface) halb-standardisierte Daten erhalten
- über Web-Scraping HTML-Inhalte von Websites herunterladen und verarbeiten
- über ferngesteuerte Browser Inhalte erheben oder Screenshots erstellen
- NutzerInnen um Datenspenden bitten
Was ist eine API?
- Austausch maschinenlesbarer Daten zwischen verschiedenen Programmen/Computern
- Formate sind standardisiert (z.B. XML oder JSON), Inhalte variieren
- Web-APIs nutzen die gleichen Protokolle wie Browser, aber liefern anderen Datenstrukturen
- oft nutzen Plattformen für ihre eigenen (Mobil-) Apps ebenfalls APIs
- mit speziellen R-Paketen können diese API-Daten wieder in R-Objekte wie z.B. Datenframes umgewandelt werden
Beispiel JSON
https://api.breakingbadquotes.xyz/v1/quotes
[
{
"quote": "La familia es todo.",
"author": "Tio Salamanca"
}
]
Workflow
- Datenquelle finden (Website, Feed, API)
- relevanten Ausgangspunkt finden (Suchanfrage, Accountname, etc.)
- Daten herunterladen
- Daten filtern und auswählen
- Daten in ein standardisiertes Format für die Analyse bringen
- (Daten quick & dirty auswerten oder visualisieren)
Buchempfehlungen



CLI-Tools in Python
- für spezifische Aufgaben gibt es zahlreiche Tools, z.B.
- Videos herunterladen -
youtube-dlp - Audio transkribieren -
whisper-ctranslate2 - Videos in Einzelbilder zerlegen -
vcsi - Python ist auf Mac und Linux-Systemen installiert, unter Windows kann es nachinstalliert werden
- Installation der einzelnen Pakete über
pip install <tool>
Zeeschuimer-Datenspende
- Firefox-Erweiterung, die beim Surfen auf bestimmten Plattformen die angezeigten Inhalte und deren Metadaten speichert
- Export als
ndjson-Datei, die man mit R einlesen kann - vor allem für Instagram und ggf. auch TikTok interessant
- sehr umfangreiche Meta-Daten, aber etwas unübersichtlich
Aufgaben bis zur übernächsten Sitzung
- Finalisieren Sie die Forschungsfragen und Hypothesen.
- Finalisieren Sie semantische und dimensionale Analyse
- Melden Sie Gruppenmitglieder und Zuständigkeiten
Forschungsdesign und Stichprobe
5-Minuten Präsentationen
Forschungsdesign
- die Grundlagen fast aller empirischen Untersuchungen ist der Vergleich
- bei der Inhaltsanalyse typische Vergleiche:
- verschiedene Medienangebote oder Plattformen
- verschiedene Kommunikatoren
- verschiedene Messzeitpunkte
- mehr als zwei Vergleichsdimensionen machen die Analyse und Ergebnisdarstellung oft komplex
Einheiten der Inhaltsanalyse
- Auswahleinheit
- Untersuchungseinheit
- Analyseeinheit
- Codiereinheit
- Kontexteinheit
Auswahl vs. Analyseeinheit
Auswahleinheit
- alle vorliegende Materialen, die aus dem gesamten Spektrum verfügbaren Medienmaterials für die Untersuchung ausgewählt werden
- Beispiel: LinkedIn-Posts der IfP-Seite (inkl. dazugehöriger Kommentare)
Analyseeinheit
- Einheit, auf die man sich bei der Interpretation beziehen will und für die ein Codebogen angelegt wird
- z.B. Beitrag, Foto, Absatz oder Aussage
Analyseeinheit: Aussage oder Beitrag?
Beitrag
- weniger aufwändig, aber ungenauer
- entspricht eher dem Verständnis der Rezipienten, weil sie aller Wahrscheinlichkeit nicht jede Aussage wahrnehmen und behalten
Aussage
- sehr aufwändig, aber ggf. genauer
- ggf. enthalten Beiträge unterschiedliche Aussagen, die man berücksichtigen will
- Herausforderung: reliable Identifikation derselben Aussagen
Stichprobenziehung
Grundgesamtheit
- Alle Botschaften (Artikel, Beiträge usw.), über die die Studie etwas aussagen soll
- Auswahl der Grundgesamtheit setzt sich zusammen aus Auswahl der Medien und Auswahl des Untersuchungszeitraums
Auswahlverfahren bei der Stichprobenbildung
- Vollerhebung (alle Einheiten)
- Zufallsauswahl (z.B. mehrstufig)
- nicht zufallsgesteuert (willkürliche, typische Fälle)
Stichprobenpraxis
- oft werden Inhalte in einer mehrstufigen Auswahl gezogen
- nicht auf allen Stufen ist derselbe Auswahlmechnismus nötig oder sinnvoll
- Beispiel:
- Auswahl von Politikeraccounts auf Instagram (gezielte Auswahl)
- Auswahl von 100 zufälligen Beiträgen aus 2025 (einfache Zufallsstichprobe)
- Auswahl jedes 5. Nutzerkommentars (bis zu 20) (systematsche Zufallsstichprobe)
Stichproben und Inferenzschlüsse
- die Auswahl der Untersuchungseinheiten bestimmt, welche Inferenzschlüsse man ziehen kann
- streng genommen sind statistische Inferenzen nur für Zufallsstichproben möglich
- Für welche zusätzlichen (unbekannten) Untersuchungseinheiten können wir Voraussagen treffen?
- Beispiel:
- Sie finden stat. signifikante Unterschiede zwischen Posts der offiziellen SPD- und FDP-TikTok-Accounts im Oktober 2025
- Auf was beziehen sich Ihre Inferenzen?
Stichprobenumfang
- je größer die Stichprobe, desto präziser die Schätzung
- Stichprobenumfang hat nichts mit Repräsentativität zu tun
Beschaffung des Materials
- Woher bekomme ich die Inhalte?
- technische Schwierigkeiten, z.B. zuverlässiges Speichern der Inhalte
- rechtliche Schwierigkeiten, z.B. Verbot in Terms of Services
- Welche Teile (Text, Bild, Video, etc.) des Beitrags werden zur Codierung benötigt?
- Kann ich die Inhalte automatisch speichern und verarbeiten?
Aufgaben bis zur nächsten Sitzung
- Finalisieren Sie die Forschungsfragen und Hypothesen.
- Diskutieren und finalisieren Sie das Untersuchungsdesign Ihrer Studie.
- Definieren Sie Untersuchungseinheit(en) und Grundgesamtheit.
- Entwickeln Sie einen konzeptionell angemessenen Stichprobenplan.
- Überlegen Sie, wie die Stichprobenziehung praktisch umgesetzt werden kann.
Sitzung 5
5-Minuten Präsentationen
Codierprozess als gelenkte Rezeption
- Problem: Informationen über die Struktur von großen Mengen von Botschaften
- Lösung 1: Selektion: Nicht alle Dimensionen der Botschaften werden berücksichtigt
- Lösung 2: Klassifikation: Die Dimensionen werden kategorisiert und gemessen
- Nachteil: Informationsverlust
- Vorteile:
- Reduktion von Komplexität
- Analyse großer Mengen von Botschaften möglich
Kategorien
- Formale Kategorien
- Medium, Autor
- Umfang des Beitrag
- Datum
- Inhaltliche Kategorien
- Themen der Artikel („Hauptthema”)
- Akteure der Artikel („Hauptakteur”)
- Urheber von Aussagen
- Tendenz/Bewertung
Kategorienbildung
- empiriegeleitet
- Auswahl von Beispielen
- Sammlung von Themen, Aussagen, Argumenten usw., die repräsentativ sind
- Identifikation der inhaltlichen Struktur und Bildung von Gruppen
- erster Kategorieentwurf
- theoriegeleitet
- Frühere Studien und Hypothesen
- Erwartung zu Inhalt und Struktur
- erster Kategorieentwurf
Kategorien im Codebuch
- Verbale Beschreibung
- “Hier wird codiert, ob der Post ein politisches Thema behandelt.”
- Information über die Indikatoren (wenn nötig)
- “Politische Themen werden codiert, wenn der Beitrag Politikfelder (z.B. Innen- oder Wirtschaftspolitik), den politischen Prozess (z.B. Wahlen) oder politische Institutionen (z.B. Bundestag) behandelt.”
- Messanweisungen i.e.S. (= Regeln für die Überführung der Daten)
- 0 = kein politisches Thema, 1 = politisches Thema
Kriterien guter Kategorien
- Kategorien müssen die Forschungsfragen beantworten können.
- Kategorien müssen trennscharf sein.
- Kategorien müssen erschöpfend sein („Sonstiges”-Kategorie)
- Kategorien müssen auf dem selben Klassifikationsprinzip beruhen, d.h. sie dürfen nur eine Dimension messen.
Strategien für Kategorien
- Multinomiale Variablen = mehrere Ausprägung
- 1 = Außenpolitik, 2 = Innenpolitik, 3 = Wirtschaftspolitik
- Problem: gleichzeitiges Auftreten mehrerer Ausprägungen
- Dummy-Codierung (Mehrfachantworten)
- V1: Außenpolitik 0/1, V2 Innenpolitik 0/1, …
- Nachteil: vielen Nullen in den Daten, Eingabe etwas aufwändiger
- Wichtig: NIE mehrere Werte in eine Zelle des Codesheets eintragen
Aufbau Codebuch
- Informationen über das Thema der Analyse
- Forschungsfragen/ Hypothesen
- Informationen über den Untersuchungszeitraum
- Definitionen der Auswahl-, Analyse, Codier- und Kontexteinheit
- Informationen über das Auswahlverfahren (Vollerhebung vs. Stichprobe)
- Definition der Zugriffskriterien
- Allgemeine Codieranweisungen
- Kategoriensystem (= alle Kategorien zusammengenommen)
- Codebogen
Aufgaben bis nächste Woche
- Finalisieren Sie Forschungsdesign und Stichprobenplan.
- Entwickeln Sie ein erstes Codebuch für die Studie.
- Erstellen Sie ein passendes Codesheet für die Dateneingabe in Excel oder Teams.
- Jedes Gruppenmitglied codiert dieselben (!) 10 Codiereinheiten, die Codierungen werden untereinander in einer Datei gesammelt.
Sitzung 7
5-Minuten Präsentationen
Wie funktioniert ein Neuronales Netz?

https://medium.com/data-science-365/overview-of-a-neural-networks-learning-process-61690a502fa
Was sind Transformer Modelle
Explainer: https://ig.ft.com/generative-ai/
Multimodale Embeddings: CLIP

https://openai.com/index/clip/
Wie funktioniert ChatGPT?
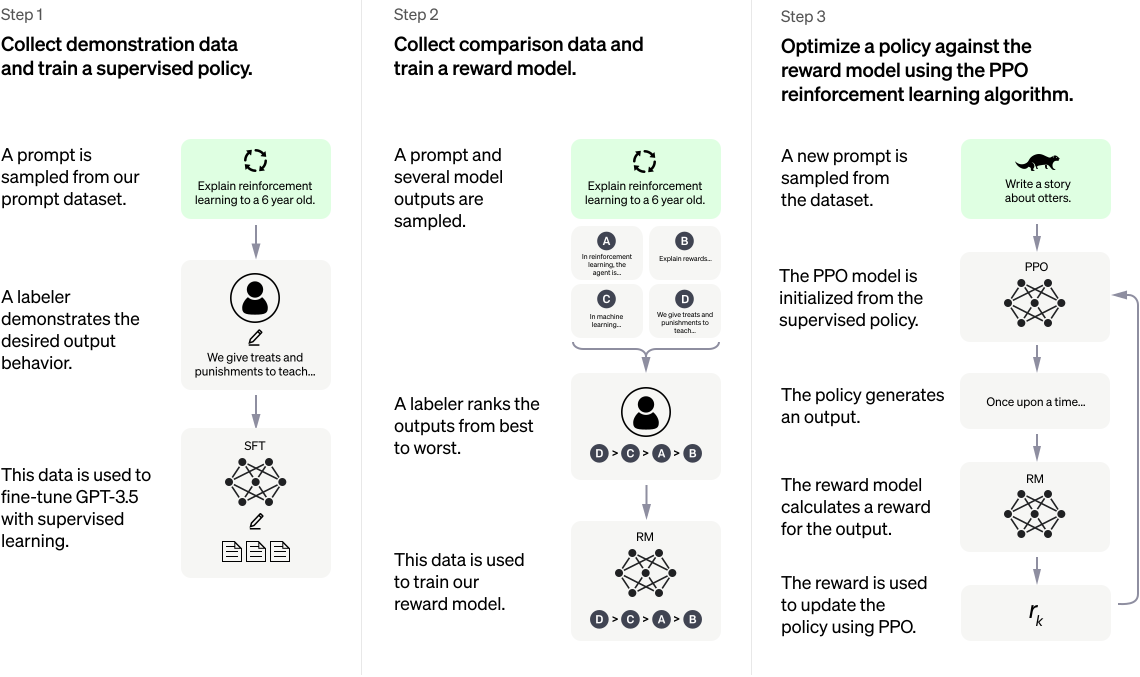
https://openai.com/blog/chatgpt
Zero-Shot-Codierung mit LLM
- LLM können verschiedene sprachliche Aufgaben “lösen”, u.a. auch inhaltsanalytische
- da die Modelle dafür nicht extra angepasst werden müssen, spricht man von Zero-Shot-Codierung
- im Gegensatz zu älteren automatischen Verfahren braucht es (fast) keine Umstellung gegenüber manuellem Codieren
- zahlreiche aktuelle Studien untersuchen, ob man manuelle Codierung durch LLM-basierte ersetzen kann
- ob und wie gut man eigene Kategorien mit LLM codieren kann, muss man ausprobieren (und machen wir)
Ablauf der LLM-Codierung
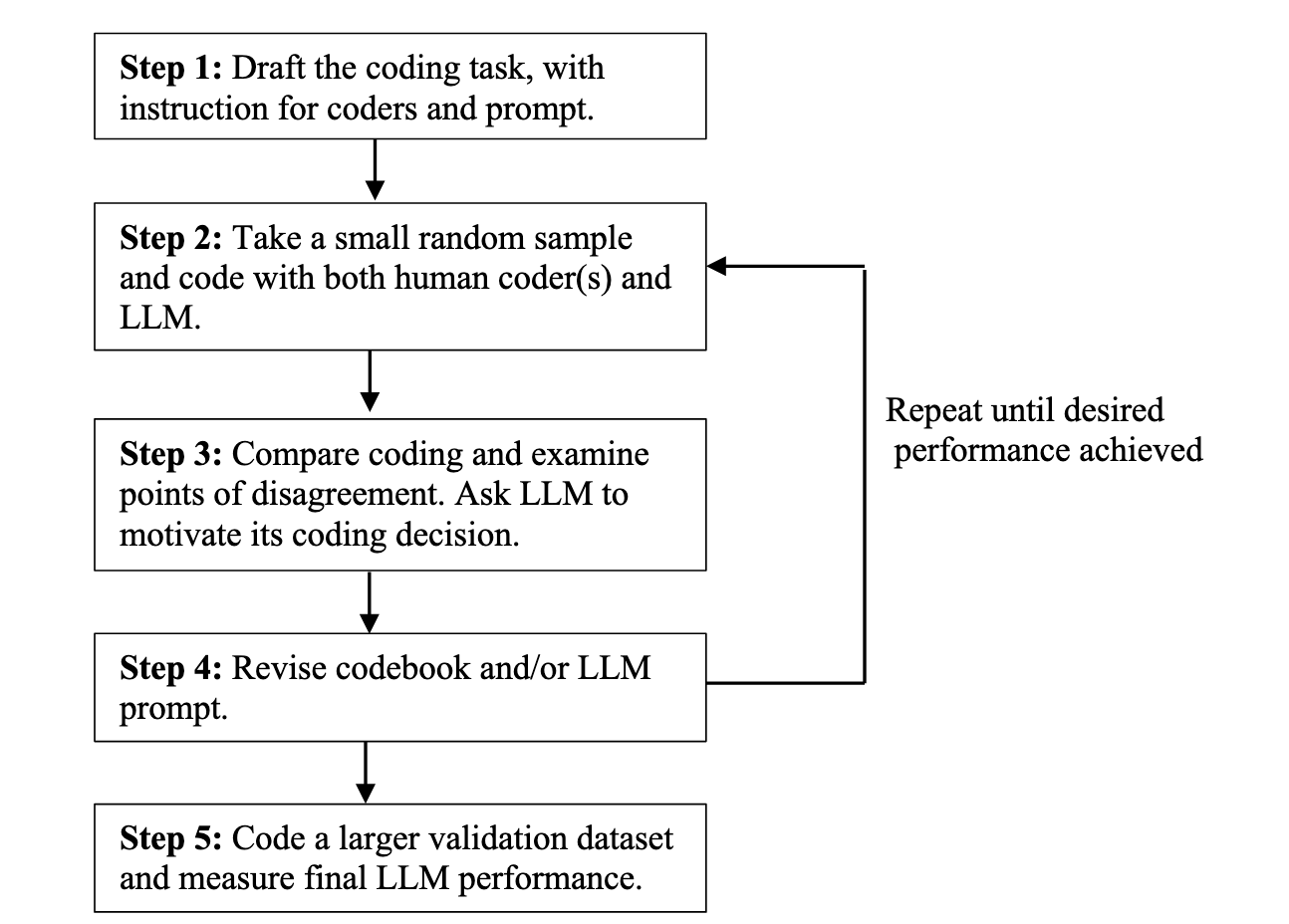
Quelle: Törnberg (2023)
Vor- und Nachteile der LLM-Codierung
- Prompts ähneln manuellen Codieranweisungen (+ etwas Prompt Engineering)
- LLM können Codierentscheidung und Begründungen liefern
- viele verschiedene kommerzielle und freie LLM sind verfügbar, Ensemble Codierung möglich
- nicht alles lässt sich leicht per LLM codieren (z.B. einfach Personen zählen)
- kommerzielle LLM kosten Geld pro Abfrage und haben ggf. Guardrails, die die Codierung verhindern bzw. erschweren
- die Nutzung von LLM ist datenschutzrechtlich und ethisch bedenklich
- multimodalle LLM sind aktuell noch sehr neu und ungetestet
- validieren, validieren, validieren!
Hausaufgabe
- Erledigen Sie die Hausaufgabe auf https://stats.ifp.uni-mainz.de/ba-ccs-track/ia-zeroshot.html
- Codieren Sie in der Gruppe 20 Codiereinheiten für einen Reliabilitätstest, d.h. einzeln (!) und jede/r dieselben (!) Fälle. Fügen Sie die Codierungen in ein Codesheet untereinander (wichtige Variablen: coder_id und unit_id).
Sitzung 8
5-Minuten Präsentationen
Gütekriterien
- Validität
- Gültigkeit der Messung
- Betrifft den gesamten Messvorgang
- Reliabilität
- Zuverlässigkeit (=Reproduzierbarkeit) der Messung
- Betrifft die eigentlich Messprozedur
- Wird aus der Übereinstimmung in der Codierung abgeleitet
Typen der Reliabilitätsmessung nach Rössler, 2017
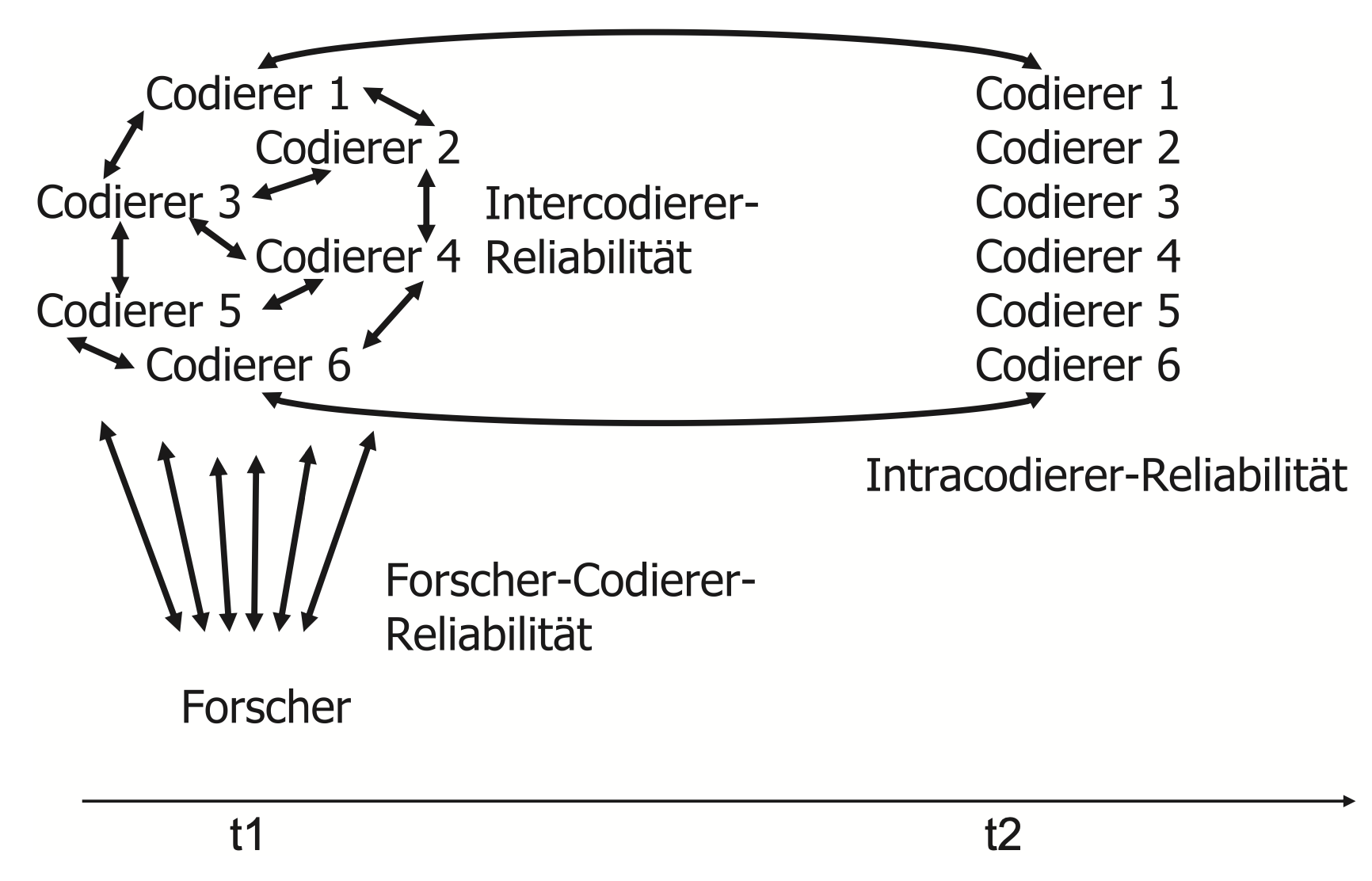
Festlegung von Übereinstimmung und Abweichung
- Für die Bewertung der Reliabilität muss zunächst festgelegt werden, was eine Übereinstimmung und Abweichung bei der Codierung darstellt.
- Einfach bei Kategorien mit dichotomer Ausprägung (“An-/Abwesenheit”).
- Schwieriger bei Kategorien mit ordinal/metrischem Niveau.
- Wie stark darf die Abweichung sein (Toleranzbereich)?
Reliablitätsindex I: Übereinstimmung nach Holsti
- Berechnet die Übereinstimmung zwischen zwei Codierern.
- Kann als prozentuale Übereinstimmung interpretiert werden.
- Ignoriert die Wahrscheinlichkeit von zufälliger Übereinstimmung, z.B. .5 bei dichotomen Variablen.
- Begrenzt aussagefähig bei sehr schiefen Verteilungen.
- Bsp.: Eine 0/1 Variable wird in 9 von 10 Fällen von Codierern A abwesend codiert (0) und ein Mal mit (1). Codierer B codiert immer 0. Holsti = .9, obwohl wir gar nicht wissen, ob die Codierer überhaupt Ausprägung 1 erkennen.
- Akzeptable Werte: nahe 1 (formale Kategorien) oder > .8 (inhaltliche Kategorien)
Reliablitätsindex II: Krippendorffs \(\alpha\)
- Gold-Standard in der Kommunikationswissenschaft für Reliabilitätstests.
- Berücksichtigt die Wahrscheinlichkeit zufälliger Übereinstimmungen, d.h. es wird geprüft, inwieweit die beobachtete Übereinstimmung über der zufälligen liegt.
- Für mehr als zwei Codierer und verschiedene Skalenniveaus geeignet.
- Akzeptable Werte wie bei Holsti (> .8), allerdings deutlich “strenger” wg. Zufallskorrektur.
Feldphase
- ca. 8-10h Codierarbeit pro Person
- Stichprobengröße ergibt sich aus Codierzeit pro Codiereinheit
- Hilfe bei Codiereinheiten/Stichprobe/Daten nur noch bis Donnerstag dieser Woche bzw. ab 8.1.2026
Aufgabe heute
- erster Reliabilitätstest
- bei Bedarf: Codebuch überarbeiten und 2. Reliabilitätstest
- Stichprobe/Datenerhebung mit mir finalisieren
Aufgaben bis 13.1.2026 (!)
- Datenerhebung abschließen, Material aufbereiten
- Codierung/Feldphase
- Erholung
Sitzung 10
5-Minuten Präsentationen
Datenbereinigung
- Fusionieren der einzelnen Codesheets
- Entfernung von Formatierungen, zusammengefassten Zellen, etc.
- Import in SPSS oder R
- Prüfen von Missings und falschen Codes (univariate Häufigkeitstabellen)
Datenaggregation
- oft entspricht Codiereinheit (z.B. Aussage) nicht Analyseeinheit (z.B. Beitrag)
- Aggregation auf Ebene der Analyseeinheit
- Berechnung von Summen- oder Mittelwertindices pro Analyseeinheit
- Prüfung durch Vergleich aggregierte vs. nicht aggregierte Zahlen
- Neuberechnung der korrekten Fallzahlen
Datenauswertung
Für jede Hypothese 3 min Schritte:
- Deskriptive Auswertung (z.B. Gruppenmittelwerte, Prozentanteile)
- inferenzstatistischer Test (t-Test, ANOVA, Chi-Quadrat-Test)
- Ergebnisdarstellung als Text, Tabelle und/oder Grafik
Hinweis: Bei 0/1 Dummy-Variablen entspricht der Mittelwert dem Anteil 1, und oft reicht es, diese zu berichten bzw. zu vergleichen.
Ergebnisteil im Projektbericht
- Beschreibung der finalen Stichprobe (allgemein relevante Informationen)
- Univariate Auswertung zentraler Variablen
- Auswertung der eigentlichen Hypothesen
- weitere interessante Analysen
Wichtig: Exaktheit, Konsistenz, Beschriftungen, etc.
Fragen?
Aufgaben heute
- Bereiten sie Ihre Codierdaten final auf und prüfen sie auf Konsistenz etc.
- Berechnen sie ggf. aggregierte Kennzahlen für die Analyse.
- Berechnen sie zentrale Kennzahlen der Stichprobe für den Ergebnisbericht.
- Planen sie die notwendigen Analyseschritte für die Hypothesentests, d.h.
- Welche Variablen sind univariat und bivariate auszuwerten?
- Welche stat. Test sind für jede Hypothese notwendig?
- Wann wäre die Hypothese wider- oder belegt? (nicht “bewiesen” oder “verifiziert”)
- Werten sie die Daten entsprechend aus.
Sitzung 13
Datenbeschreibung I: univariat
Datenbeschreibung II: gruppiert
Statistisches Modell
| Parameter | Coefficient | CI | CI_low | CI_high | t | df_error | p | Std_Coefficient | Std_Coefficient_CI_low | Std_Coefficient_CI_high | Fit | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | (Intercept) | 82.63636 | 0.95 | 59.253610 | 106.01912 | 7.227991 | 29 | 0.0000001 | -0.9341957 | -1.2752368 | -0.5931546 | NA |
| 2 | cyl [6] | 39.64935 | 0.95 | 2.153528 | 77.14517 | 2.162695 | 29 | 0.0389489 | NA | NA | NA | NA |
| 3 | cyl [8] | 126.57792 | 0.95 | 95.331403 | 157.82444 | 8.285112 | 29 | 0.0000000 | NA | NA | NA | NA |
| 4 | NA | NA | NA | NA | NA | NA | NA | NA | 0.5782919 | 0.0314095 | 1.1251742 | NA |
| 5 | NA | NA | NA | NA | NA | NA | NA | NA | 1.8461585 | 1.3904232 | 2.3018938 | NA |
| 6 | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA |
| 7 | AIC | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | 328.3299068 |
| 8 | AICc | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | 329.8113882 |
| 9 | BIC | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | 334.1928504 |
| 10 | R2 | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | 0.7138734 |
| 11 | R2 (adj.) | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | 0.6941406 |
| 13 | Sigma | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | 37.9183929 |
Modellvorhersagen
cyl Estimate Std. Error z Pr(>|z|) S 2.5 % 97.5 %
4 82.6 11.4 7.23 <0.001 40.9 60.2 105
6 122.3 14.3 8.53 <0.001 56.0 94.2 150
8 209.2 10.1 20.64 <0.001 312.1 189.4 229
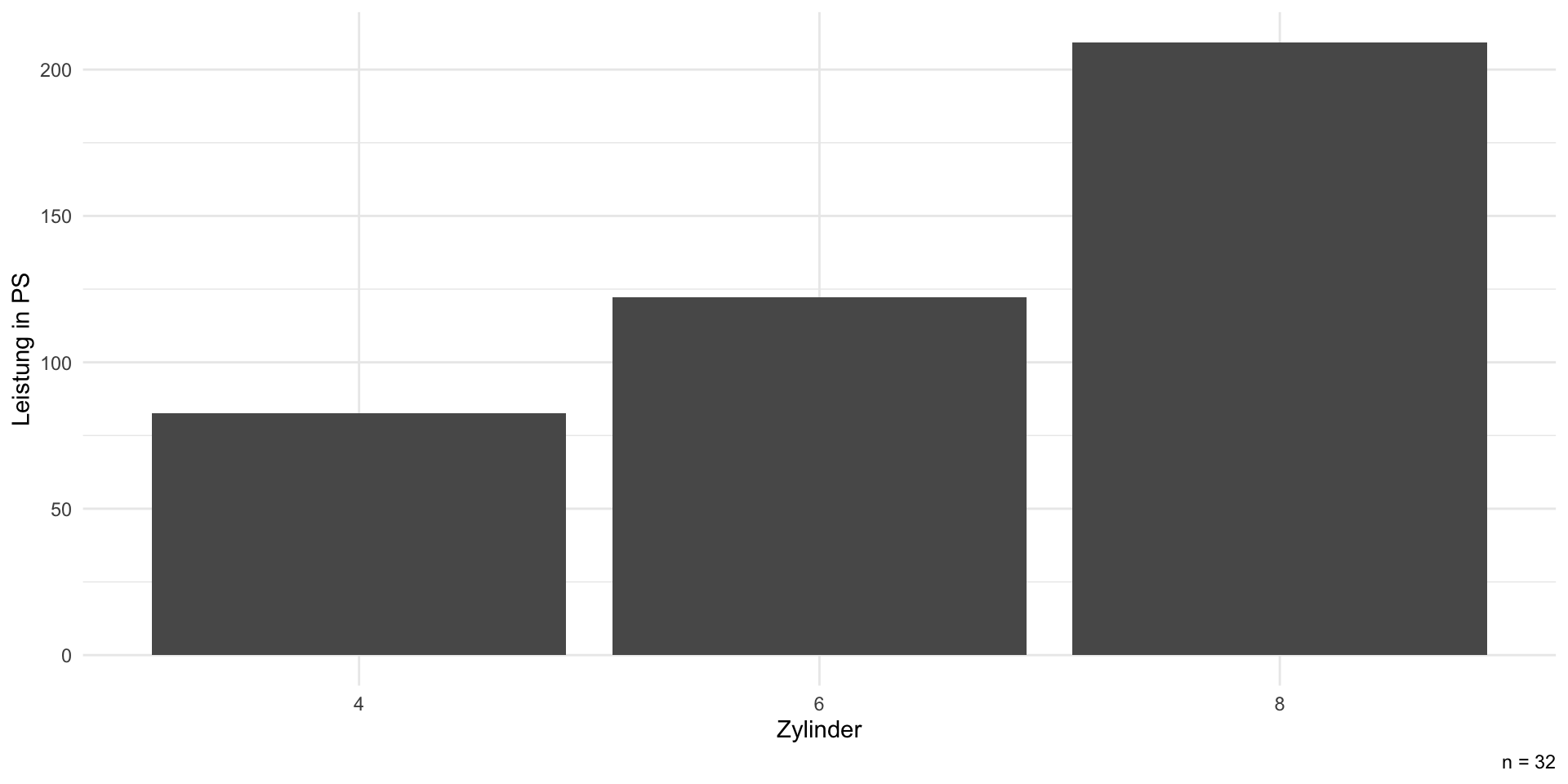
Type: responseVisualisierung I: deskriptiv
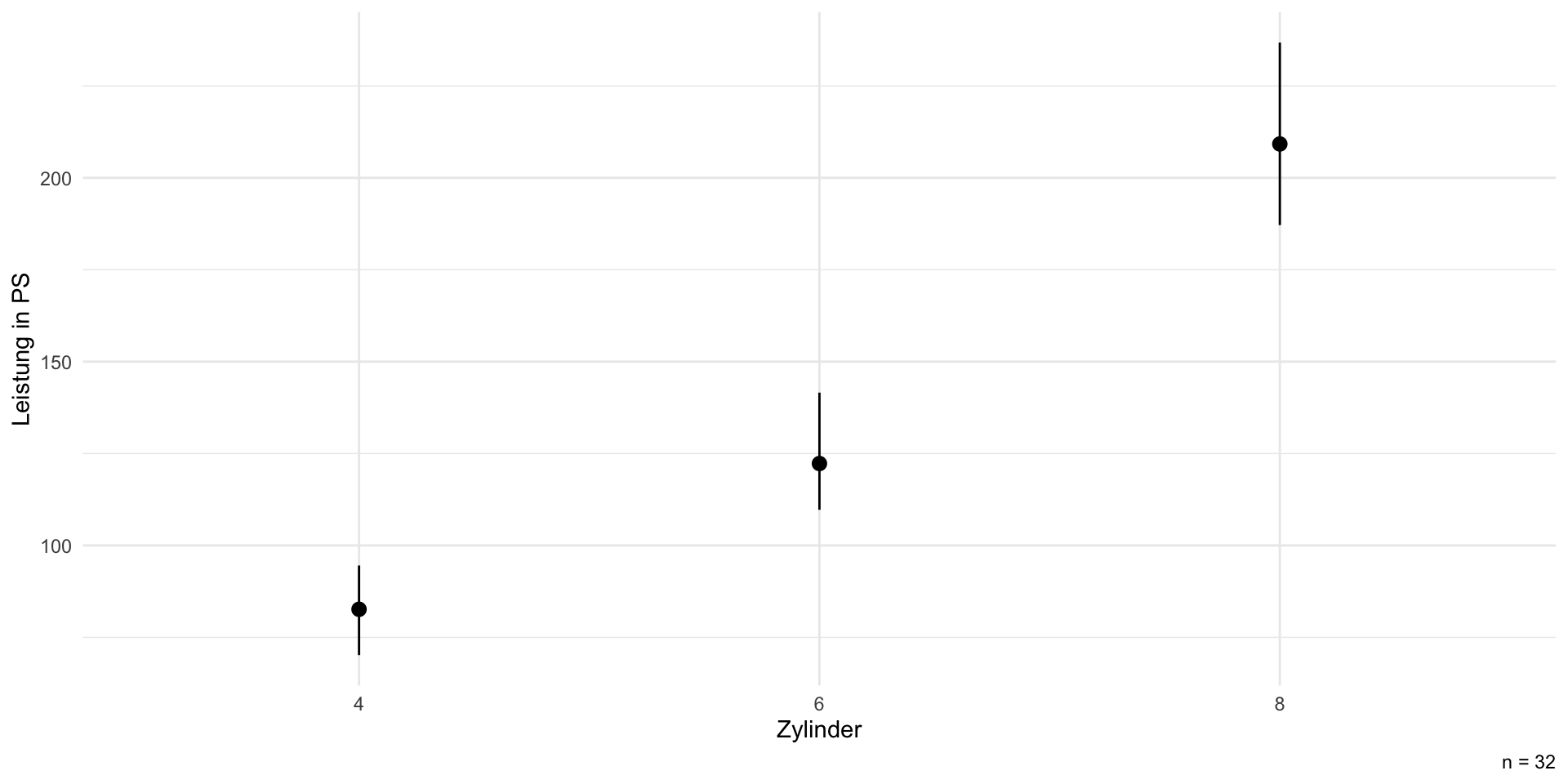
Visualisierung II: mit CI
Visualisierung III: modellbasiert
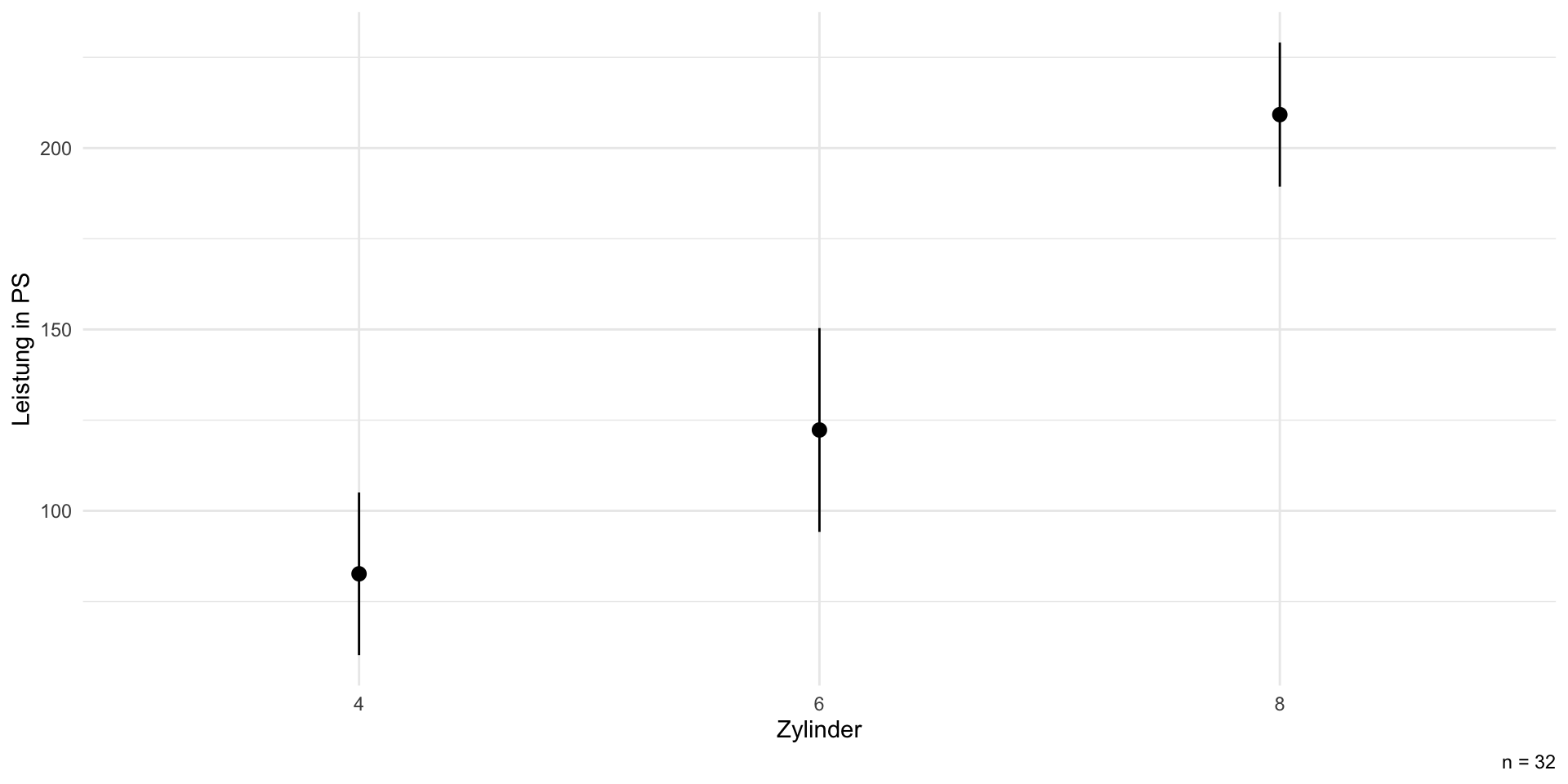
Deskriptiv vs. modellbasierte Visualisierung
- deskriptive Darstellung passt zu den (Roh-)Daten
- modellbasierte Darstellung passt zum statistischen Test (= basiert auf demselben Modell)
- modellbasierte Darstellung korrigiert ggf. Verzerrung (z.B. bei geschachtelten Daten)
- funktioniert besonders gut bei komplexeren (multivariaten) Analysen
- Moderationsanalysen z.B. durch unterschiedliche Farben visualisieren
Tipps
report::report_table()(plus ggf.summary()) ist sehr vielseitig- Visualisierung mit ggplot (
theme_minimalodertinythemes::theme_ipsum_rc) - Darstellung von statistischer Unsicherheit über Konfidenzintervalle
- eigene Farben und Themes sehr leicht möglich (z.B.
remotes::install_github('Mikata-Project/ggthemr')) - ggplot2 Grafiken abspeichern mit
ggsave("myplot.png", width = 8, height = 4.5)
Projektbericht I
- Kennzeichnung der eigenen Arbeitsleistung ist verpflichtend (entweder auf dem Deckblatt oder unter der Kapitelüberschrift)
- Gruppennote ist der Standard, ggf. Wunsch nach Einzelbenotung in der Abgabe-Email vermerken
- Eidesstattliche Erklärung anfügen
- Sie dürfen KI-Tools (sinnvoll!) nutzen, die Arbeit müssen Sie selbst schreiben (Kennzeichnungspflicht!).
- elektronische Abgabe per E-Mail von Codebuch, Codesheet, Hausarbeit und Analyseskript (R, SPSS, Excel) an scharkow@uni-mainz.de
- Weitere Informationen (Deckblatt, Schriftgröße, etc.) gibt es auf der Webseite des Instituts für Publizistik
Projektbericht II
- ca. 10 Seiten pro Gruppenmitglied, maximal (!) 10.000 Wörter insgesamt. Es gilt Qualität vor Quantität
- relevante Grafiken und Tabellen in den Text, ergänzende Analysen in den Anhang
- Dokumentation der eigenen Arbeit, d.h. Berichte können recycled werden
- es muss nichts “rauskommen”, außer dass Sie etwas gelernt haben
- Formalien und Regeln wissenschaftlicher Arbeit sind wichtig und notenrelevant
- sprachliche und formale Endredaktion lohnt sich, ebenso schöne Aufbereitung der Ergebnisse
Projektbericht III
- übliche Gliederung jeder empirischen Studie (gern an Fachartikeln orientieren)
- zentrale Begriffe sind zu definieren, Forschungsfragen und Hypothesen sind (aus der Literatur) herzuleiten
- methodisches Vorgehen ist zu erläutern und zu begründen (u.a. Stichprobe, Codebuch, Reliabilität, etc.)
- Abbildungen und Tabellen sind verständlich (!) zu beschriften (inkl. Fallzahl!)
- Ergebnisse sind inhaltlich zu interpretieren und in den Forschungsstand einzuordnen
- (Was ist neu? Was wurde bestätigt? Was nicht? Praktische Implikationen? Weitere Forschung?)
Aufgaben heute
- Analysen aufbereiten und visualisieren
- Ergebnispräsentation (1-2 Folien FF+Hypothesen, 1-2 Folien Methoden, 3-5 Folien Ergebnisse)
- Präsentation maximal 10 min nächste Woche (gern nur 1 Vortragende/r)
Sitzung 14
Abschlusspräsentationen
Feedback
Fragen?
Danke fürs Mitmachen!
Literatur
Benoit, K., Laver, M., & Mikhaylov, S. (2009). Treating Words as Data with Error: Uncertainty in Text Statements of Policy Positions. American Journal of Political Science, 53(2), 495–513. https://doi.org/10.1111/j.1540-5907.2009.00383.x
Kromrey, H., Roose, J., & Strübing, J. (2016). Empirische sozialforschung: Modelle und methoden der standardisierten datenerhebung und datenauswertung (Vol. 1040). Utb.
Törnberg, P. (2023). How to use LLMs for text analysis. https://arxiv.org/pdf/2307.13106
Social Media Plattformen